Knowledge graphs and LLMs are the building blocks of the most recent advancements happening in the world of artificial intelligence (AI). Combining knowledge graphs (KGs) and LLMs produces a system that has access to a vast network of factual information and can understand complex language.
The system has the potential to use this accessibility to answer questions, generate textual outputs, and engage with other NLP tasks. This blog aims to explore the potential of integrating knowledge graphs and LLMs, navigating through the promise of revolutionizing AI.
Introducing knowledge graphs and LLMs
Before we understand the impact and methods of integrating KGs and LLMs, let’s visit the definition of the two concepts.
What are knowledge graphs (KGs)?
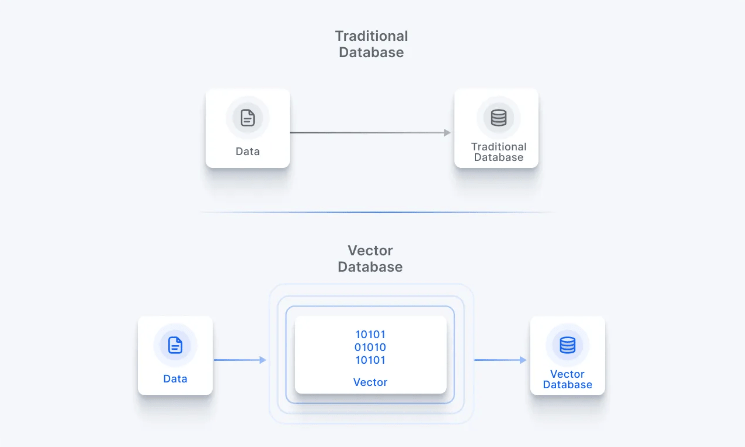
They are a visual web of information that focuses on connecting factual data in a meaningful manner. Each set of data is represented as a node with edges building connections between them. This representational storage of data allows a computer to recognize information and relationships between the data points.
KGs organize data to highlight connections and new relationships in a dataset. Moreover, it enabled improved search results as knowledge graphs integrate the contextual information to provide more relevant results.
What are large language models (LLMs)?
LLMs are a powerful tool within the world of AI using deep learning techniques for general-purpose language generation and other natural language processing (NLP) tasks. They train on massive amounts of textual data to produce human-quality texts.
Large language models have revolutionized human-computer interactions with the potential for further advancements. However, LLMs are limited in the factual grounding of their results. It makes LLMs able to produce high-quality and grammatically accurate results that can be factually inaccurate.
An overview of knowledge graphs and LLMs – Source: arXiv
Combining KGs and LLMs
Within the world of AI and NLP, integrating the concepts of KGs and LLMs has the potential to open up new avenues of exploration. While knowledge graphs cannot understand language, they are good at storing factual data. Unlike KGs, LLMs excel in language understanding but lack factual grounding.
Combining the two entities brings forward a solution that addresses the weaknesses of both. The strengths of KGs and LLMs cover each concept’s limitations, producing more accurate and better-represented results.
Frameworks to combine KGs and LLMs
It is one thing to talk about combining knowledge graphs and large language models, implementing the idea requires planning and research. So far, researchers have explored three different frameworks aiming to integrate KGs and LLMs for enhanced outputs.
Frameworks for integrating KGs and LLMs – Source: arXiv
KG-enhanced LLMs
This framework focuses on using knowledge graphs for training LLMs. The factual knowledge and relationship links in the KGs become accessible to the LLMs in addition to the traditional textual data during the training phase. A LLM can then learn from the information available in KGs.
As a result, LLMs can get a boost in factual accuracy and grounding by incorporating the data from KGs. It will also enable the models to fact-check the outputs and produce more accurate and informative results.
LLM-augmented KGs
This design shifts the structure of the first framework. Instead of KGs enhancing LLMs, they leverage the reasoning power of large language models to improve knowledge graphs. It makes LLMs smart assistants to improve the output of KGs, curating their information representation.
Moreover, this framework can leverage LLMs to find problems and inconsistencies in information connections of KGs. The high reasoning of LLMs also enables them to infer new relationships in a knowledge graph, enriching its outputs.
This builds a pathway to create more comprehensive and reliable knowledge graphs, benefiting from the reasoning and inference abilities of LLMs.
This framework proposes a mutually beneficial relationship between the two AI components. Each entity works to improve the other through a feedback loop. It is designed in the form of a continuous learning cycle between LLMs and KGs.
It can be viewed as a concept that combines the two above-mentioned frameworks into a single design where knowledge graphs enhance language model outputs and LLMs analyze and improve KGs.
It results in a dynamic cycle where KGs and LLMs constantly improve each other. The iterative design of this integration framework leads to a more powerful and intelligent system overall.
While we have looked at the three different frameworks of integration of KGs and LLMs, the synergized LLMs + KGs is the most advanced approach in this field. It promises to unlock the full potential of both entities, supporting the creation of superior AI systems with enhanced reasoning, knowledge representation, and text generation capabilities.
Future of LLM and KG integration
Combining the powers of knowledge graphs and large language models holds immense potential in various fields. Some plausible possibilities are discussed below.
Educational revolution
With access to knowledge graphs, LLMs can generate personalized educational content for students, encompassing a wide range of subjects and topics. The data can be used to generate interactive lessons, provide detailed feedback, and answer questions with factual accuracy.
Enhancing scientific research
The integrated frameworks provide an ability to analyze vast amounts of scientific data, identify patterns, and even suggest new hypotheses. The combination has the potential to accelerate scientific research across various fields.
Intelligent customer service
With useful knowledge representations of KGs, LLMs can generate personalized and more accurate support. It will also enhance their ability to troubleshoot issues and offer improved recommendations, providing an intelligent customer experience to the users of any enterprise.
Thus, the integration of knowledge graphs and LLMs has the potential to boost the development of AI-powered tasks and transform the field of NLP.
If I were to ask you, can Generative AI in education outperform students in competitive assessments like that of Harvard’s or Stanford’s, what would your answer be? Maybe? Let me tell you, the answer is yes.
That’s the exciting world of generative AI, shaking things up everywhere across the globe, be it logical assessments, medical exams, or a thought-provoking essay at the Ivy Leagues.
Now, before you imagine robots taking over classrooms, hold on! Generative AI isn’t here to replace humans, it’s more of a super-powered sidekick for education.
From unequal access to education to stressed-out teachers and confused students, the education landscape faces a lot of challenges. Generative AI isn’t here to steal anyone’s job, but maybe, it can help us fix the problems, ushering in a new era of learning and creativity.
Should ChatGPT be banned in schools?
Role of AI in Education
Here’s how generative AI is reshaping the education landscape:
Personalized learning
Traditionally, education has relied on a standardized approach. This “one-size-fits-all” method often leaves students behind or bored, failing to cater to their individual learning styles and paces. Generative AI disrupts this model by tailoring the education experience to individual students’ needs.
With the help of vast amounts of data, it adapts the learning content, pace, and style to suit the strengths, weaknesses, and preferences of each learner, ensuring that no student is left behind.
This personalized approach accommodates different learning styles, such as visual, auditory, reading-writing, or kinesthetic, ensuring that students receive tailored support based on their unique preferences and abilities, while also providing immediate feedback and support.
AI in Action
For instance, Duolingoleverages generative AI to create personalized learning experiences for young children. The app tailors its content based on a child’s progress, offering interactive activities, games, and even AI-generated stories that reinforce learning. In addition, Khan Academy has launchedKhanmigo, an AI tutor that assists young students in various subjects on its platform.
Popular Generative AI Applications in the EdTech Landscape – Source: Reach Capital
Accessibility and Inclusivity: Breaking Barriers for All
Traditionally, access to quality education has been heavily reliant on individuals’ geographical access and socio-economic background. Generative AI disrupts this norm by delivering high-quality educational resources directly to students, regardless of their backgrounds.
Now, people in remote areas with limited access to knowledge bases, diverse learning environments, and styles, can leverage Generative AI, for personalized tutoring and learning.
Generative AI further promotes inclusivity and global collaboration by facilitating language learning through the translation of educational content into multiple languages and adapting materials to fit local cultural contexts. It plays a crucial role in developing inclusive and accessible educational content suitable for diverse learner populations.
Moreover, Generative AI can be personalized to support students with special needs by providing customized learning experiences through assistive functions and communication technologies. This ensures that students with diverse requirements have access to top-quality learning materials.
Curious how generative AI is reshaping the education landscape? Learn what an expert educator has to say!
AI in Action
For instance, Dreamreader is an AI-powered platform that tailors reading experiences to a student’s reading level and interests. It generates personalized stories with adjustable difficulty, keeping students engaged and motivated to improve their reading skills.
As technology becomes more accessible, platforms are emerging that enable anyone, even those without coding skills, to create their own “Chat GPT bots,” opening doors of accessibility for all.
Beyond Textbooks: Immersive Learning Adventures
Generative AI has also fostered the emergence of hybrid schools, virtual classrooms, remote learning, and micro-learning, allowing students to access education beyond the confines of a traditional classroom, and opening up a world of limitless learning opportunities.
Generative AI can transport students to the heart of historical events, conduct virtual experiments in a simulated lab, or even practice a new language with an AI-powered conversation partner.
AI in Action
Platforms like Historyverseand Hellohistory.AI are prime examples. This AI-powered platform allows students to step into historical simulations, interacting with virtual characters and environments to gain a deeper understanding of the past.
Support for Educators: AI as a Partner in Progress
Far from replacing teachers, generative AI is here to empower them. With personalized lesson planning and content creation, AI-assisted evaluation and feedback, intelligent tutoring systems, and virtual teaching assistants, AI can free up valuable teacher time.
This allows educators to focus on what they do best: fostering student engagement, providing personalized instruction, and pursuing professional development.In a future where AI can be a leading source of disseminating information and taking the lead in delivering information, it becomes crucial to reconsider our approach towards education.
Rather than sticking to traditional classrooms, picture a flipped classroom model, a hybrid learning setup where students can engage in remote self-learning and use physical classrooms for interactive group activities and collaborative learning. It’s all about blending the best of both worlds for a more effective and engaging educational experience.
Generative AI is reshaping the roles and dynamics of the education system, encouraging educators to evolve from knowledge deliverers to facilitators. They need to become mentors who guide and encourage student agency, fostering a collaborative environment built on co-agency and collective intelligence.
AI in Action
Take a look at GradeScope, a product by Turnitin, a real-world example of generative AI empowering teachers. This platform uses AI to automate the time-consuming task of grading written assignments. Teachers upload student work, and GradeScope utilizes AI to analyze handwriting, identify key concepts, and even provide students with initial grading and personalized feedback.
This frees up valuable teacher time, allowing them to focus on more individualized instruction, like one-on-one conferences or in-depth discussions about student writing. This is the power of generative AI as a partner in education – it empowers teachers to do what they do best: inspire, guide, and unlock the potential in every student
Here’s what every educator must know!
Shift towards Metacognitive Continuous Learning
Generative AI is ushering in a new era of “metacognitive continuous learning”. This approach to assessment focuses on students’ ability to understand, monitor, and regulate their cognitive and metacognitive processes, making it an integral part of the learning process.
In metacognitive continuous learning, students not only acquire knowledge but also reflect on their learning strategies and adapt them as needed. They actively engage in self-regulation to optimize their learning experience and become aware of their thinking processes.
AI systems help students recognize their strengths and weaknesses, suggest strategies for improvement, and promote a deeper understanding of the subject matter. By leveraging AI-supported feedback, students develop essential skills for lifelong learning.
This shift represents a move away from traditional tests that measure memory recall or specific skills and towards a more student-centered and flexible approach to learning, making students self-directed learners.
It recognizes that learning is not just about acquiring knowledge but also about understanding how we think and continuously improving our learning strategies and focusing on personal growth.
Critical Skills to Survive and Thrive in an AI-driven World
While generative AI offers a treasure trove of educational content, it’s crucial to remember that information literacy is essential. Students need to develop the ability to critically evaluate AI-generated content, assessing its accuracy, and biases, leveraging AI to augment their own capabilities rather than blindly relying on it.
Here is a range of key skills that learners need to develop to thrive and adapt. These skills include:
Critical Thinking: Learners must develop the ability to analyze information, evaluate its credibility, and make informed decisions. Critical thinking allows individuals to effectively navigate the vast amount of data and AI-generated content available.
Problem-solving: AI presents new challenges and complexities. Learners need to be able to identify and define problems, think creatively, and develop innovative solutions. Problem-solving skills enable individuals to leverage AI technology to address real-world issues.
Adaptability: The rapid pace of technological change requires learners to be adaptable. They must embrace change, learn new tools and technologies quickly, and be willing to continuously evolve their knowledge and skills.
Data and AI Literacy: With AI generating vast amounts of data, learners need to develop the ability to understand, interpret, and analyze data so that they can make data-driven decisions and leverage AI technologies effectively. They must also possess AI literacy skills to navigate AI-driven platforms, understand the ethical implications of AI, and effectively use digital tools for learning and work.
The Human Edge: Fostering Creativity, Emotional Intelligence, and Intuition: While AI excels at crunching numbers and following patterns, certain qualities remain uniquely human and will continue to be valuable in the age of AI. AI can generate content, but it takes human imagination to truly push boundaries and come up with groundbreaking ideas.
Our ability to empathize, build relationships, and navigate complex social situations will remain crucial for success in various fields. In addition, the ability to tap into our intuition and make gut decisions can be a valuable asset, even in the age of data-driven decision-making.
Can AI truly replace humans? Let’s find out now
Effectively Leveraging Generative AI for Education: The PAIR Framework
To equip students with critical thinking and problem-solving skills in the age of AI, the PAIR framework is a very useful tool. This four-step approach integrates generative AI tools into assignments, encouraging students to actively engage with the technology.
Problem Formulation:
The journey begins with students defining the problem or challenge they want to tackle. This initial step fosters critical thinking and sets the stage for their AI-powered exploration.
AI Tool Selection:
Students become discerning consumers of technology by learning to explore, compare, and evaluate different generative AI tools. Understanding available features allows them to choose the most appropriate tool for their specific problem.
Interaction:
Armed with their chosen AI tool, students put their problem-solving skills to the test. They experiment with various inputs and outputs, observing how the tool influences their approach and the outcome.
Reflection:
The final step involves critical reflection. Students assess their experience with the generative AI tool, reporting on its strengths, weaknesses, and overall impact on their learning process. This reflection solidifies their understanding and helps them become more self-aware learners.
By incorporating the PAIR framework, students develop the skills necessary to navigate the world of AI, becoming not just passive users, but empowered learners who can leverage technology to enhance their problem-solving abilities.
The Road Ahead: Challenges, Considerations, and Responsible Implementation
As with any new technology, generative AI comes with its own set of challenges. Ensuring that AI systems are trained on unbiased data sets is crucial to prevent perpetuating stereotypes or misinformation. Additionally, it’s important to remember that the human element remains irreplaceable in education.
Academic Dishonesty
AI tools can be misused for plagiarism, with students using them to generate essays or complete assignments without truly understanding the content.
Rather than outright banning these tools, educational institutions need to promote ethical and responsible AI usage. This entails establishing transparent guidelines and policies to deter dishonest or unethical practices.
Accuracy and Bias
Generative AI models are trained on vast amounts of data, which can perpetuate biases or inaccuracies present in that data. They are often trained on datasets that may not adequately represent the cultural and contextual diversity of different regions.
This can lead to a lack of relevance and inclusivity in AI-generated content. Uncritical use of AI-generated content could lead students to faulty information.
In addition, localization efforts are needed to ensure that generative AI systems are sensitive to cultural nuances and reflect diverse perspectives.
Overdependence on Technology
Overreliance on AI tools for learning can hinder critical thinking and problem-solving skills. Students may become accustomed to having solutions generated for them, rather than developing the ability to think independently.
Educating users about AI’s limitations, potential risks, and responsible usage, becomes extremely important. It is important to promote AI as a tool designed to augment human capabilities rather than holding them back.
Readiness Disparities
While generative AI offers tremendous potential for improving accessibility and inclusion in education, on some occasions, it can also exacerbate existing disparities.
The integration of generative AI hinges on “technological readiness” – meaning adequate infrastructure, reliable internet access, proper training, and digital literacy.
These factors can vary greatly between regions and countries. Unequal access to these resources could create a situation where generative AI widens, rather than shrinks, the educational gap between developed and developing nations.
These disparities must be addressed to ensure that generative AI reaches all students, regardless of their background, ensuring a more equitable society.
Way Forward: A Balanced Approach
Market projection of AI in education – Source: Yahoo Finance
Generative AI undoubtedly holds the potential to reshape the education landscape, by providing personalized learning, improving content, automating tasks, and reducing barriers to education.
To successfully leverage these benefits, a balanced approach is necessary that promotes responsible integration of AI in educational settings, while preserving the human touch.Moreover, it is crucial to empower educators and learners with the relevant skills and competencies to effectively utilize Generative AI while also fostering dialogue and collaboration among stakeholders.
By striking a balance between leveraging its potential benefits and mitigating the associated risks, the equitable integration of Generative AI in education can be achieved, creating a dynamic and adaptive learning environment that empowers students for the future.
Natural language processing (NLP) and large language models (LLMs) have been revolutionized with the introduction of transformer models. These refer to a type of neural network architecture that excels at tasks involving sequences.
While we have talked about the details of a typical transformer architecture, in this blog we will explore the different types of the models.
How to categorize transformer models?
Transformers ensure the efficiency of LLMs in processing information. Their role is critical to ensure improved accuracy, faster training on data, and wider applicability. Hence, it is important to understand the different model types available to choose the right one for your needs.
However, before we delve into the many types of transformer models, it is important to understand the basis of their classification.
Classification by transformer architecture
The most fundamental categorization of transformer models is done based on their architecture. The variations are designed to perform specific tasks or cater to the limitations of the base architecture. The very common model types under this category include encoder-only, decoder-only, and encoder-decoder transformers.
Categorization based on pre-training approaches
While architecture is a basic component of consideration, the training techniques are equally crucial components for transformers. Pre-training approaches refer to the techniques used to train a transformer on a general dataset before finetuning it to perform specific tasks.
Some common approaches that define classification under this category include Masked Language Models (MLMs), autoregressive models, and conditional transformers.
This presents a general outlook on classifying transformer models. While we now know the types present under each broader category, let’s dig deeper into each transformer model type.
As the name suggests, this architectural type uses only the encoder part of the transformer, focusing on encoding the input sequence. For this model type, understanding the input sequence is crucial while generating an output sequence is not required.
Some common applications of an encoder-only transformer include:
Text classification
It is focused on classifying the input data based on defined parameters. It is often used in email spam filters to categorize incoming emails. The transformer model can also train over the patterns for effective filtration of unwanted messages.
Sentimental analysis
This feature makes it an appropriate choice for social media companies to analyze customer feedback and their emotion toward a service or product. It provides useful data insights, leading to the creation of effective strategies to enhance customer satisfaction.
Anomaly detection
It is particularly useful for finance companies. The analysis of financial transactions allows the timely detection of anomalies. Hence, possible fraudulent activities can be addressed promptly.
Other uses of an encoder-only transformer include question-answering, speech recognition, and image captioning.
Decoder-only transformer
It is a less common type of transformer model that uses only the decoder component to generate text sequences based on input prompts. The self-attention mechanism allows the model to focus on previously generated outputs in the sequence, enabling it to refine the output and create more contextually aware results.
Some common uses of decoder-only transformers include:
Text summarization
It can iteratively generate textual summaries of the input, focusing on including the important aspects of information.
Text generation
It builds on a provided prompt to generate relevant textual outputs. The results cover a diverse range of content types, like poems, codes, and snippets. It is capable of iterating the process to create connected and improved responses.
Chatbots
It is useful to handle conversational interactions via chatbots. The decoder can also consider previous conversations to formulate relevant responses.
This is a classic architectural type of transformer, efficiently handling sequence-to-sequence tasks, where you need to transform one type of sequence (like text) into another (like a translation or summary). An encoder processes the input sequence while a decoder is used to generate an output sequence.
Some common uses of an encoder-decoder transformer include:
Machine translation
Since the sequence is important at both the input and output, it makes this transformer model a useful tool for translation. It also considers contextual references and relationships between words in both languages.
Text summarization
While this use overlaps with that of a decoder-only transformer, text summarization differs from an encoder-decoder transformer due to its focus on the input sequence. It enables the creation of summaries that focus on relevant aspects of the text highlighted in an input prompt.
Question-answering
It is important to understand the question before providing a relevant answer. An encoder-decoder transformer allows this focus on both ends of the communication, ensuring each question is understood and answered appropriately.
This concludes our exploration of architecture-based transformer models. Let’s explore the classification from the lens of pre-training approaches.
Categorization based on pre-training approaches
While the architectural differences provide a basis for transformer types, the models can be further classified based on their techniques of pre-training.
Let’s explore the various transformer models segregated based on pre-training approaches.
Masked Language Models (MLMs)
Models with this pre-training approach are usually encoder-only in architecture. They are trained to predict a masked word in a sentence based on the contextual information of the surrounding words. The training enables these model types to become efficient in understanding language relationships.
Some common MLM applications are:
Boosting downstream NLP tasks
MLMs train on massive datasets, enabling the models to develop a strong understanding of language context and relationships between words. This knowledge enables MLM models to contribute and excel in diverse NLP applications.
General-purpose NLP tool
The enhanced learning, knowledge, and adaptability of MLMs make them a part of multiple NLP applications. Developers leverage this versatility of pre-trained MLMs to build a basis for different NLP tools.
Efficient NLP development
The pre-trained foundation of MLMs reduces the time and resources needed for the deployment of NLP applications. It promotes innovation, faster development, and efficiency.
Autoregressive models
Typically built using a decoder-only architecture, this pre-training model is used to generate sequences iteratively. It can predict the next word based on the previous one in the text you have written. Some common uses of autoregressive models include:
Text generation
The iterative prediction from the model enables it to generate different text formats. From codes and poems to musical pieces, it can create all while iteratively refining the output as well.
Chatbots
The model can also be utilized in a conversational environment, creating engaging and contextually relevant responses,
Machine translation
While encoder-decoder models are commonly used for translation tasks, some languages with complex grammatical structures are supported by autoregressive models.
Conditional transformer
This transformer model incorporates the additional information of a condition along with the main input sequence. It enables the model to generate highly specific outputs based on particular conditions, ensuring more personalized results.
Some uses of conditional transformers include:
Machine translation with adaptation
The conditional aspect enables the model to set the target language as a condition. It ensures better adjustment of the model to the target language’s style and characteristics.
Summarization with constraints
Additional information allows the model to generate summaries of textual inputs based on particular conditions.
Speech recognition with constraints
With the consideration of additional factors like speaker ID or background noise, the recognition process enhances to produce improved results.
Future of transformer model types
While numerous transformer model variations are available, the ongoing research promises their further exploration and growth. Some major points of further development will focus on efficiency, specialization for various tasks, and integration of transformers with other AI techniques.
Transformers can also play a crucial role in the field of human-computer interaction with their enhanced capabilities. The growth of transformers will definitely impact the future of AI. However, it is important to understand the uses of each variation of a transformer model before you choose the one that fits your requirements.
In the dynamic field of artificial intelligence, Large Language Models (LLMs) are groundbreaking innovations shaping how we interact with digital environments. These sophisticated models, trained on vast collections of text, have the extraordinary ability to comprehend and generate text that mirrors human language, powering a variety of applications from virtual assistants to automated content creation.
The essence of LLMs lies not only in their initial training but significantly in fine-tuning, a crucial step to refine these models for specialized tasks and ensure their outputs align with human expectations.
Introduction to finetuning
Finetuning LLMs involves adjusting pre-trained models to perform specific functions more effectively, enhancing their utility across different applications. This process is essential because, despite the broad knowledge base acquired through initial training, LLMs often require customization to excel in particular domains or tasks.
For instance, a model trained on a general dataset might need fine-tuning to understand the nuances of medical language or legal jargon, making it more relevant and effective in those contexts.
Enter Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), two leading methodologies for finetuning LLMs. RLHF utilizes a sophisticated feedback loop, incorporating human evaluations and a reward model to guide the AI’s learning process.
On the other hand, DPO adopts a more straightforward approach, directly applying human preferences to influence the model’s adjustments. Both strategies aim to enhance model performance and ensure the outputs are in tune with user needs, yet they operate on distinct principles and methodologies.
This blog post aims to unfold the layers of RLHF and DPO, drawing a comparative analysis to elucidate their mechanisms, strengths, and optimal use cases.
Understanding these fine-tuning methods paves the path to deploying LLMs that not only boast high performance but also resonate deeply with human intent and preferences, marking a significant step towards achieving more intuitive and effective AI-driven solutions.
Examples of how fine-tuning improves performance in practical applications
Customer Service Chatbots: Fine-tuning an LLM on customer service transcripts can enhance its ability to understand and respond to user queries accurately, improving customer satisfaction.
Legal Document Analysis: By fine-tuning on legal texts, LLMs can become adept at navigating complex legal language, aiding in tasks like contract review or legal research.
Medical Diagnosis Support: LLMs fine-tuned with medical data can assist healthcare professionals by providing more accurate information retrieval and patient interaction, thus enhancing diagnostic processes.
Delving into reinforcement learning from human feedback (RLHF)
Explanation of RLHF and its components
Reinforcement Learning from Human Feedback (RLHF) is a technique used to fine-tune AI models, particularly language models, to enhance their performance based on human feedback.
The core components of RLHF include the language model being fine-tuned, the reward model that evaluates the language model’s outputs, and the human feedback that informs the reward model. This process ensures that the language model produces outputs more aligned with human preferences.
Theoretical foundations of RLHF
RLHF is grounded in reinforcement learning, where the model learns from actions rather than from a static dataset.
Unlike supervised learning, where models learn from labeled data or unsupervised learning, where models identify patterns in data, reinforcement learning models learn from the consequences of their actions, guided by rewards. In RLHF, the “reward” is determined by human feedback, which signifies the model’s success in generating desirable outputs.
Pretraining the language model with self-supervision
Data Gathering: The process begins by collecting a vast and diverse dataset, typically encompassing a wide range of topics, languages, and writing styles. This dataset serves as the initial training ground for the language model.
Self-Supervised Learning: Using this dataset, the model undergoes self-supervised learning. Here, the model is trained to predict parts of the text given other parts. For instance, it might predict the next word in a sentence based on the previous words. This phase helps the model grasp the basics of language, including grammar, syntax, and some level of contextual understanding.
Foundation Building: The outcome of this stage is a foundational model that has a general understanding of language. It can generate text and understand some context but lacks specialization or fine-tuning for specific tasks or preferences.
Ranking model’s outputs based on human feedback
Generation and Evaluation: Once pretraining is complete, the model starts generating text outputs, which are then evaluated by humans. This could involve tasks like completing sentences, answering questions, or engaging in dialogue.
Scoring System: Human evaluators use a scoring system to rate each output. They consider factors like how relevant, coherent, or engaging the text is. This feedback is crucial as it introduces the model to human preferences and standards.
Adjustment for Bias and Diversity: Care is taken to ensure the diversity of evaluators and mitigate biases in feedback. This helps in creating a balanced and fair assessment criterion for the model’s outputs.
Modeling Human Judgment: The scores and feedback from human evaluators are then used to train a separate model, known as the reward model. This model aims to understand and predict the scores human evaluators would give to any piece of text generated by the language model.
Feedback Loop: The reward model effectively creates a feedback loop. It learns to distinguish between high-quality and low-quality outputs based on human ratings, encapsulating the criteria humans use to judge the text.
Iteration for Improvement: This step might involve several iterations of feedback collection and reward model adjustment to accurately capture human preferences.
Finetuning the language model using feedback from the reward model
Integration of Feedback: The insights gained from the reward model are used to fine-tune the language model. This involves adjusting the model’s parameters to increase the likelihood of generating text that aligns with the rewarded behaviors.
Reinforcement Learning Techniques: Techniques such as Proximal Policy Optimization (PPO) are employed to methodically adjust the model. The model is encouraged to “explore” different ways of generating text but is “rewarded” more when it produces outputs that are likely to receive higher scores from the reward model.
Continuous Improvement: This fine-tuning process is iterative and can be repeated with new sets of human feedback and reward model adjustments, continuously improving the language model’s alignment with human preferences.
The iterative process of RLHF allows for continuous improvement of the language model’s outputs. Through repeated cycles of feedback and adjustment, the model refines its approach to generating text, becoming better at producing outputs that meet human standards of quality and relevance.
Using a reward model for finetuning LLMs – Source: nownextlater.ai
Exploring direct preference optimization (DPO)
Introduction to the concept of DPO as a direct approach
Direct Preference Optimization (DPO) represents a streamlined method for fine-tuning large language models (LLMs) by directly incorporating human preferences into the training process.
This technique simplifies the adaptation of AI systems to better meet user needs, bypassing the complexities associated with constructing and utilizing reward models.
Theoretical foundations of DPO
DPO is predicated on the principle that direct human feedback can effectively guide the development of AI behavior.
By directly using human preferences as a training signal, DPO simplifies the alignment process, framing it as a direct learning task. This method proves to be both efficient and effective, offering advantages over traditional reinforcement learning approaches like RLHF.
Training the language model through self-supervision
Data Preparation: The model starts with self-supervised learning, where it is exposed to a wide array of text data. This could include everything from books and articles to websites, encompassing a variety of topics, styles, and contexts.
Learning Mechanism: During this phase, the model learns to predict text sequences, essentially filling in blanks or predicting subsequent words based on the preceding context. This method helps the model to grasp the fundamentals of language structure, syntax, and semantics without explicit task-oriented instructions.
Outcome: The result is a baseline language model capable of understanding and generating coherent text, ready for further specialization based on specific human preferences.
Collecting pairs of examples and obtaining human ratings
Generation of Comparative Outputs: The model generates pairs of text outputs, which might vary in tone, style, or content focus. These pairs are then presented to human evaluators in a comparative format, asking which of the two better meets certain criteria such as clarity, relevance, or engagement.
Human Interaction: Evaluators provide their preferences, which are recorded as direct feedback. This step is crucial for capturing nuanced human judgments that might not be apparent from purely quantitative data.
Feedback Incorporation: The preferences gathered from this comparison form the foundational data for the next phase of optimization. This approach ensures that the model’s tuning is directly influenced by human evaluations, making it more aligned with actual user expectations and preferences.
Training the model using a cross-entropy-based loss function
Optimization Technique: Armed with pairs of examples and corresponding human preferences, the model undergoes fine-tuning using a binary cross-entropy loss function. This statistical method compares the model’s output against the preferred outcomes, quantifying how well the model’s predictions match the chosen preferences.
Adjustment Process: The model’s parameters are adjusted to minimize the loss function, effectively making the preferred outputs more likely in future generations. This process iteratively improves the model’s alignment with human preferences, refining its ability to generate text that resonates with users.
Constraining the model to maintain its generativity
Balancing Act: While the model is being fine-tuned to align closely with human preferences, it’s vital to ensure that it doesn’t lose its generative diversity. The process involves carefully adjusting the model to incorporate feedback without overfitting to specific examples or restricting its creative capacity.
Ensuring Flexibility: Techniques and safeguards are put in place to ensure the model remains capable of generating a wide range of responses. This includes regular evaluations of the model’s output diversity and implementing mechanisms to prevent the narrowing of its generative abilities.
Outcome: The final model retains its ability to produce varied and innovative text while being significantly more aligned with human preferences, demonstrating an enhanced capability to engage users in a meaningful way.
DPO eliminates the need for a separate reward model by treating the language model’s adjustment as a direct optimization problem based on human feedback. This simplification reduces the layers of complexity typically involved in model training, making the process more efficient and directly focused on aligning AI outputs with user preferences.
Comparative analysis: RLHF vs. DPO
After exploring both Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), we’re now at a point where we can compare these two key methods used to fine-tune Large Language Models (LLMs). This side-by-side look aims to clarify the differences and help decide which method might be better for certain situations.
Direct comparison
Training Efficiency: RLHF involves several steps, including pre-training, collecting feedback, training a reward model, and then fine-tuning. This process is detailed and requires a lot of computer power and setup time. On the other hand, DPO is simpler and more straightforward because it optimizes the model directly based on what people prefer, often leading to quicker results.
Data Requirements: RLHF uses a variety of feedback, such as scores or written comments, which means it needs a wide range of input to train well. DPO, however, focuses on comparing pairs of options to see which one people like more, making it easier to collect the needed data.
Model Performance: RLHF is very flexible and can be fine-tuned to perform well in complex situations by understanding detailed feedback. DPO is great for making quick adjustments to align with what users want, although it might not handle varied feedback as well as RLHF.
Scalability: RLHF’s detailed process can make it hard to scale up due to its high computer resource needs. DPO’s simpler approach means it can be scaled more easily, which is particularly beneficial for projects with limited resources.
Pros and cons
Advantages of RLHF: Its ability to work with many kinds of feedback gives RLHF an edge in tasks that need detailed customization. This makes it well-suited for projects that require a deep understanding and nuanced adjustments.
Disadvantages of RLHF: The main drawback is its complexity and the need for a reward model, which makes it more demanding in terms of computational resources and setup. Also, the quality and variety of feedback can significantly influence how well the fine-tuning works.
Advantages of DPO: DPO’s more straightforward process means faster adjustments and less demand on computational resources. It integrates human preferences directly, leading to a tight alignment with what users expect.
Disadvantages of DPO: The main issue with DPO is that it might not do as well with tasks needing more nuanced feedback, as it relies on binary choices. Also, gathering a large amount of human-annotated data might be challenging.
Ideal Use Cases for RLHF: RLHF excels in scenarios requiring customized outputs, like developing chatbots or systems that need to understand the context deeply. Its ability to process complex feedback makes it highly effective for these uses.
Ideal Use Cases for DPO: When you need quick AI model adjustments and have limited computational resources, DPO is the way to go. It’s especially useful for tasks like adjusting sentiments in text or decisions that boil down to yes/no choices, where its direct approach to optimization can be fully utilized.
Feature
RLHF
DPO
Training Efficiency
Multi-step and computationally intensive due to the iterative nature and involvement of a reward model.
More straightforward and computationally efficient by directly using human preferences, often leading to faster convergence.
Data Requirements
Requires diverse feedback, including numerical ratings and textual annotations, necessitating a comprehensive mix of responses.
Generally relies on pairs of examples with human ratings, simplifying the preference learning process with less complex input.
Model Performance
Offers adaptability and nuanced influence, potentially leading to superior performance in complex scenarios.
Efficient in quickly aligning model outputs with user preferences but may lack flexibility for varied feedback.
Scalability
May face scalability challenges due to computational demands but is robust across diverse tasks.
Easier to scale in terms of computational demands, suitable for projects with limited resources.
Advantages
Flexible handling of diverse feedback types; suitable for detailed output shaping and complex tasks.
Simplified and rapid fine-tuning process; directly incorporates human preferences with fewer computational resources.
Disadvantages
Complex setup and higher computational costs; quality and diversity of feedback can affect outcomes.
May struggle with complex feedback beyond binary choices; gathering a large amount of annotated data could be challenging.
Ideal Use Cases
Best for tasks requiring personalized or tailored outputs, such as conversational agents or context-rich content generation.
Well-suited for projects needing quick adjustments and closely aligned with human preferences, like sentiment analysis or binary decision systems.
Summarizing key insights and applications
As we wrap up our journey through the comparative analysis of Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) for fine-tuning Large Language Models (LLMs), a few key insights stand out.
Both methods offer unique advantages and cater to different needs in the realm of AI development. Here’s a recap and some guidance on choosing the right approach for your project.
Recap of fundamental takeaways
RLHF is a detailed, multi-step process that provides deep customization potential through the use of a reward model. It’s particularly suited for complex tasks where nuanced feedback is crucial.
DPO simplifies the fine-tuning process by directly applying human preferences, offering a quicker and less resource-intensive path to model optimization.
Choosing the right finetuning method
The decision between RLHF and DPO should be guided by several factors:
Task Complexity: If your project involves complex interactions or requires understanding nuanced human feedback, RLHF might be the better choice. For more straightforward tasks or when quick adjustments are needed, DPO could be more effective.
Available Resources: Consider your computational resources and the availability of human annotators. DPO is generally less demanding in terms of computational power and can be more straightforward in gathering the necessary data.
Desired Control Level: RLHF offers more granular control over the fine-tuning process, while DPO provides a direct route to aligning model outputs with user preferences. Evaluate how much control and precision you need in the fine-tuning process.
The future of finetuning LLMs
Looking ahead, the field of LLM fine-tuning is ripe for innovation. We can anticipate advancements that further streamline these processes, reduce computational demands, and enhance the ability to capture and apply complex human feedback.
Additionally, the integration of AI ethics into fine-tuning methods is becoming increasingly important, ensuring that models not only perform well but also operate fairly and without bias. As we continue to push the boundaries of what AI can achieve, the evolution of fine-tuning methods like RLHF and DPO will play a crucial role in making AI more adaptable, efficient, and aligned with human values.
By carefully considering the specific needs of each project and staying informed about advancements in the field, developers can leverage these powerful tools to create AI systems that are not only technologically advanced but also deeply attuned to the complexities of human communication and preferences.
Have you ever read a sentence in a book that caught you off guard with its meaning? Maybe it started in one direction and then, suddenly, the meaning changed, making you stumble and re-read it. These are known as garden-path sentences, and they are at the heart of a fascinating study on human cognition—a study that also sheds light on the capabilities of AI, specifically the language model ChatGPT.
Certainly! Here is a comparison table outlining the key aspects of language processing in ChatGPT versus humans based on the study:
Feature
ChatGPT
Humans
Context Use
Utilizes previous context to predict what comes next.
Uses prior context and background knowledge to anticipate and integrate new information.
Predictive Capabilities
Can predict human memory performance in language-based tasks .
Naturally predict and create expectations about upcoming information.
Memory Performance
Relatedness ratings by ChatGPT correspond with actual memory performance.
Proven correlation between relatedness and memory retention, especially in the presence of fitting context.
Processing Manner
Processes information autoregressively, using the preceding context to anticipate future elements .
Sequentially processes language, constructing and updating mental models based on predictions.
Error Handling
Requires updates in case of discrepancies between predictions and actual information .
Creation of breakpoints and new mental models in case of prediction errors.
Cognitive Faculties
Lacks an actual memory system, but uses relatedness as a proxy for foreseeing memory retention.
Employs cognitive functions to process, comprehend, and remember language-based information.
Language Processing
Mimics certain cognitive processes despite not being based on human cognition.
Complex interplay of cognitive mechanisms for language comprehension and memory.
Applications
Potential to assist in personalized learning and cognitive enhancements, especially in diverse and elderly groups.
Continuous learning and cognitive abilities that could benefit from AI-powered enhancement strategies
This comparison table synthesizes the congruencies and distinctions discussed in the research, providing a broad understanding of how ChatGPT and humans process language and the potential for AI-assisted advancements in cognitive performance.
The Intrigue of Garden-Path Sentences
Certainly! Garden-path sentences are a unique and useful tool for linguists and psychologists studying human language processing and memory. These sentences are constructed in a way that initially leads the reader to interpret them incorrectly, often causing confusion or a momentary misunderstanding. The term “garden-path” refers to the idiom “to be led down the garden path,” meaning to be deceived or misled.
Usually, the first part of a garden-path sentence sets up an expectation that is violated by the later part, which forces the reader to go back and reinterpret the sentence structure to make sense of it. This reanalysis process is of great interest to researchers because it reveals how people construct meaning from language, how they deal with syntactic ambiguity, and how comprehension and memory interact.
The classic example given,
“The old man the boat,”
relies on the structural ambiguity of the word “man.”
Initially, “The old man” reads like a noun phrase, leading you to expect a verb to follow.
But as you read “the boat,” confusion arises because “the boat” doesn’t function as a verb.
Here’s where the garden-path effect comes into play:
To make sense of the sentence, you must realize “man” is being used as a verb, meaning to operate or staff, and “the old” functions as the subject. The corrected interpretation is that older individuals are the ones operating the boat.
Other examples of garden-path sentences might include:
“The horse raced past the barn and fell.” At first read, you might think the sentence is complete after “barn,” making “fell” seem out of place. However, the sentence means the horse that was raced past the barn is the one that fell.
“The complex houses married and single soldiers and their families.” Initially, “complex” might seem to be an adjective modifying “houses,” but “houses” is in fact a verb, and “the complex” refers to a housing complex.
These sentences demonstrate the cognitive work involved in parsing and understanding language. By examining how people react to and remember such sentences, researchers can gain insights into the psychological processes underlying language comprehension and memory formation
ChatGPT’s Predictive Capability
Garden-path sentences, with their inherent complexity and potential to mislead readers temporarily, have allowed researchers to observe the processes involved in human language comprehension and memory. The study at the core of this discussion aimed to push boundaries further by exploring whether an AI model, specifically ChatGPT, could predict human memory performance concerning these sentences.
The study presented participants with pairs of sentences, where the second sentence was a challenging garden-path sentence, and the first sentence provided context. This context was either fitting, meaning it was supportive and related to the garden-path sentence, making it easier to comprehend, or unfitting, where the context was not supportive and made comprehension more challenging.
ChatGPT, mirroring human cognitive processes to some extent, was used to assess the relatedness of these two sentences and to predict the memorability of the garden-path sentence.
The participants then participated in a memory task to see how well they recalled the garden-path sentences. The correlation between ChatGPT’s predictions and human performance was significant, suggesting that ChatGPT could indeed forecast how well humans would remember sentences based on the context provided.
For instance, if the first sentence was
“Jane gave up on the diet,” followed by the garden-path sentence
“Eating carrots sticks to your ribs,” the fitting context (“sticks” refers to adhering to a diet plan), makes it easier for both humans and
ChatGPT to make the sentence memorable. On the contrary, an unfitting context like
“The weather is changing” would offer no clarity, making the garden-path sentence less memorable due to a lack of relatability.
This reveals the role of context and relatability in language processing and memory. Sentences placed in a fitting context were rated as more memorable and, indeed, better remembered in subsequent tests. This alignment between AI assessments and human memory performance underscores ChatGPT’s predictive capability and the importance of cohesive information in language retention.
Memory Performance in Fitting vs. Unfitting Contexts
In the study under discussion, the experiment involved presenting participants with two types of sentence pairs. Each pair consisted of an initial context-setting sentence (Sentence 1) and a subsequent garden-path sentence (Sentence 2), which is a type of sentence designed to lead the reader to an initial misinterpretation.
In a “fitting” context, the first sentence provided would logically lead into the garden-path sentence, aiding comprehension by setting up the correct framework for interpretation.
For example, if Sentence 1 was “The city has no parks,” and Sentence 2 was “The ducks the children feed are at the lake,” the concept of feed here would fit with the absence of city parks, and the readers can easily understand that “the children feed” is a descriptive action relating to “the ducks.”
Conversely, in an “unfitting” context, the first sentence would not provide a supportive backdrop for the garden-path sentence, making it harder to parse and potentially less memorable.
If Sentence 1 was “John is a skilled carpenter,” and Sentence 2 remained “The ducks the children feed are at the lake,” the relationship between Sentence 1 and Sentence 2 is not clear because carpentry has no apparent connection to feeding ducks or the lake.
Participants in the study were asked to first rate the relatedness of these two sentences on a scale. The study found that participants rated fitting contexts as more related than unfitting ones.
The second part of the task was a surprise memory test where only garden-path sentences were presented, and the participants were required to recall them. It was discovered that the garden-path sentences that had a preceding fitting context were better remembered than those with an unfitting context—this indicated that context plays a critical role in how we process and retain sentences.
ChatGPT, a generative AI system, predicted this outcome. The model also rated garden-path sentences as more memorable when they had a fitting context, similar to human participants, demonstrating its capability to forecast memory performance based on context.
This highlights not only the role of context in human memory but also the potential for AI to predict human cognitive processes.
Stochastic Reasoning: A Potential Cognitive Mechanism
The study in question introduces the notion of stochastic reasoning as a potential cognitive mechanism affecting memory performance. Stochastic reasoning involves a probabilistic approach to understanding the availability of familiar information, also known as retrieval cues, which are instrumental in bolstering memory recall.
The presence of related, coherent information can elevate activation within our cognitive processes, leading to an increased likelihood of recalling that information later on.
Let’s consider an example to elucidate this concept. Imagine you are provided with the following two sentences as part of the study:
“The lawyer argued the case.”
“The evidence was compelling.”
In this case, the two sentences provide a fitting context where the first sentence creates a foundation of understanding related to legal scenarios and the second sentence builds upon that context by introducing “compelling evidence,” which is a familiar concept within the realm of law.
This clear and potent relation between the two sentences forms strong retrieval cues that enhance memory performance, as your brain more easily links “compelling evidence” with “lawyer argued the case,” which aids in later recollection.
Alternatively, if the second sentence was entirely unrelated, such as “The roses in the garden are in full bloom,” the lack of a fitting context would mean weak or absent retrieval cues. As the information related to law does not connect well with the concept of blooming roses, this results in less effective memory performance due to the disjointed nature of the information being processed.
The study found that when sentences are placed within a fitting context that aligns well with our existing knowledge and background, the relationship between the sentences is clear, thus providing stronger cues that streamline the retrieval process and lead to better retention and recall of information.
This reflects the significance of stochastic reasoning and the role of familiarity and coherence in enhancing memory performance.
ChatGPT vs. Human Language Processing
The paragraph delves into the intriguing observation that ChatGPT, a language model developed by OpenAI, and humans share a commonality in how they process language despite the underlying differences in their “operating systems” or cognitive architectures 1. Both seem to rely significantly on the surrounding context to comprehend incoming information and to integrate it coherently with the preceding context.
To illustrate, consider the following example of a garden-path sentence: “The old man the boat.” This sentence is confusing at first because “man” is often used as a verb, and the reader initially interprets “the old man” as a noun phrase.
The confusion is cleared up when provided with a fitting context, such as “elderly people are in control.” Now, the phrase makes sense—’man’ is understood as a verb meaning ‘to staff,’ and the garden-path sentence is interpreted correctly to mean that elderly people are the ones operating the boat.
However, if the preceding sentence was unrelated, such as “The birds flew to the south,” there is no helpful context to parse “The old man the boat” correctly, and it remains confusing, illustrating an unfitting context. This unfitness affects the recall of the garden-path sentence in the memory task, as it lacks clear, coherent links to preexisting knowledge or context that facilitate understanding and later recall.
The study’s findings depicted that when humans assess two sentences as being more related, which is naturally higher in fitting contexts than in unfitting ones, the memory performance for the ambiguous (garden-path) sentence also improves.
In a compelling parallel, ChatGPT generated similar assessments when given the same sentences, assigning higher relatedness values to fitting contexts over unfitting ones. This correlation suggests a similarity in how ChatGPT and humans use context to parse and remember new information.
Furthermore, the relatedness ratings were not just abstract assessments but tied directly to the actual memorability of the sentences. As with humans, ChatGPT’s predictions of memorability were also higher for sentences in fitting contexts, a phenomenon that may stem from its sophisticated language processing capabilities that crudely mimic cognitive processes involved in human memory.
This similarity in the use of context and its impact on memory retention is remarkable, considering the different mechanisms through which humans and machine learning models operate.
Broader Implications and the Future
The paragraph outlines the wider ramifications of the research findings on the predictive capabilities of generative AI like ChatGPT regarding human memory performance in language tasks. The research suggests that these AI models could have practical applications in several domains, including:
Education:
AI could be used to tailor learning experiences for students with diverse cognitive needs. By understanding how different students retain information, AI applications could guide educators in adjusting teaching materials, pace, and instructional approaches to cater to individual learning styles and abilities.
For example, if a student is struggling with remembering historical dates, the AI might suggest teaching methods or materials that align with their learning patterns to improve retention.
Eldercare:
The study indicates that older adults often face a cognitive slowdown, which could lead to more frequent memory problems. AI, once trained on data taking into account individual cognitive differences, could aid in developing personalized cognitive training and therapy plans aimed at enhancing mental functions in the elderly.
For instance, a cognitive enhancement program might be customized for an older adult who has difficulty recalling names or recent events by using strategies found effective through AI analysis.
Impact of AI on human cognition
The implications here go beyond just predicting human behavior; they extend to potentially improving cognitive processes through the intervention of AI.
These potential applications represent a synergistic relationship between AI and human cognitive research, where the insights gained from one field can materially benefit the other.
Furthermore, adaptive AI systems could continually learn and improve their predictions and recommendations based on new data, thereby creating a dynamic and responsive tool for cognitive enhancement and education.
While we provided a detailed guideline on understanding RAG and finetuning, a comparative analysis of the two provides a deeper insight. Let’s explore and address the RAG vs finetuning debate to determine the best tool to optimize LLM performance.
RAG vs finetuning LLM – A detailed comparison of the techniques
It’s crucial to grasp that these methodologies while targeting the enhancement of large language models (LLMs), operate under distinct paradigms. Recognizing their strengths and limitations is essential for effectively leveraging them in various AI applications.
This understanding allows developers and researchers to make informed decisions about which technique to employ based on the specific needs of their projects. Whether it’s adapting to dynamic information, customizing linguistic styles, managing data requirements, or ensuring domain-specific performance, each approach has its unique advantages.
By comprehensively understanding these differences, you’ll be equipped to choose the most suitable method—or a blend of both—to achieve your objectives in developing sophisticated, responsive, and accurate AI models.
Summarizing the RAG vs finetuning comparison
Team RAG or team Fine-Tuning? Tune in to this podcast now to find out their specific benefits, trade-offs, use-cases, enterprise adoption, and more!
Adaptability to dynamic information
RAG shines in environments where information is constantly updated. By design, RAG leverages external data sources to fetch the latest information, making it inherently adaptable to changes.
This quality ensures that responses generated by RAG-powered models remain accurate and relevant, a crucial advantage for applications like real-time news summarization or updating factual content.
Fine-tuning, in contrast, optimizes a model’s performance for specific tasks through targeted training on a curated dataset.
While it significantly enhances the model’s expertise in the chosen domain, its adaptability to new or evolving information is constrained. The model’s knowledge remains as current as its last training session, necessitating regular updates to maintain accuracy in rapidly changing fields.
Customization and linguistic style
RAG‘s primary focus is on enriching responses with accurate, up-to-date information retrieved from external databases.
This process, though excellent for fact-based accuracy, means RAG models might not tailor their linguistic style as closely to specific user preferences or nuanced domain-specific terminologies without integrating additional customization techniques.
Fine-tuning excels in personalizing the model to a high degree, allowing it to mimic specific linguistic styles, adhere to unique domain terminologies, and align with particular content tones.
This is achieved by training the model on a dataset meticulously prepared to reflect the desired characteristics, enabling the fine-tuned model to produce outputs that closely match the specified requirements.
Data efficiency and requirements
RAG operates by leveraging external datasets for retrieval, thus requiring a sophisticated setup to manage and query these vast data repositories efficiently.
The model’s effectiveness is directly tied to the quality and breadth of its connected databases, demanding rigorous data management but not necessarily a large volume of labeled training data.
Fine-tuning, however, depends on a substantial, well-curated dataset specific to the task at hand.
It requires less external data infrastructure compared to RAG but relies heavily on the availability of high-quality, domain-specific training data. This makes fine-tuning particularly effective in scenarios where detailed, task-specific performance is paramount and suitable training data is accessible.
Efficiency and scalability
RAG is generally considered cost-effective and efficient for a wide range of applications, particularly because it can dynamically access and utilize information from external sources without the need for continuous retraining.
This efficiency makes RAG a scalable solution for applications requiring access to the latest information or coverage across diverse topics.
Fine-tuning demands a significant investment in time and resources for the initial training phase, especially in preparing the domain-specific dataset and computational costs.
However, once fine-tuned, the model can operate with high efficiency within its specialized domain. The scalability of fine-tuning is more nuanced, as extending the model’s expertise to new domains requires additional rounds of fine-tuning with respective datasets.
RAG demonstrates exceptional versatility in handling queries across a wide range of domains by fetching relevant information from its external databases.
Its performance is notably robust in scenarios where access to wide-ranging or continuously updated information is critical for generating accurate responses.
Fine-tuning is the go-to approach for achieving unparalleled depth and precision within a specific domain.
By intensively training the model on targeted datasets, fine-tuning ensures the model’s outputs are not only accurate but deeply aligned with the domain’s subtleties, making it ideal for specialized applications requiring high expertise.
Hybrid approach: Enhancing LLMs with RAG and finetuning
The concept of a hybrid model that integrates Retrieval-Augmented Generation (RAG) with fine-tuning presents an interesting advancement. This approach allows for the contextual enrichment of LLM responses with up-to-date information while ensuring that outputs are tailored to the nuanced requirements of specific tasks.
Such a model can operate flexibly, serving as either a versatile, all-encompassing system or as an ensemble of specialized models, each optimized for particular use cases.
In practical applications, this could range from customer service chatbots that pull the latest policy details to enrich responses and then tailor these responses to individual user queries, to medical research assistants that retrieve the latest clinical data for accurate information dissemination, adjusted for layman understanding.
The hybrid model thus promises not only improved accuracy by grounding responses in factual, relevant data but also ensures that these responses are closely aligned with specific domain languages and terminologies.
However, this integration introduces complexities in model management, potentially higher computational demands, and the need for effective data strategies to harness the full benefits of both RAG and fine-tuning.
Despite these challenges, the hybrid approach marks a significant step forward in AI, offering models that combine broad knowledge access with deep domain expertise, paving the way for more sophisticated and adaptable AI solutions.
Choosing the best approach: Finetuning, RAG, or hybrid
Choosing between fine-tuning, Retrieval-Augmented Generation (RAG), or a hybrid approach for enhancing a Large Language Model should consider specific project needs, data accessibility, and the desired outcome alongside computational resources and scalability.
Fine-tuning is best when you have extensive domain-specific data and seek to tailor the LLM’s outputs closely to specific requirements, making it a perfect fit for projects like creating specialized educational content that adapts to curriculum changes. RAG, with its dynamic retrieval capability, suits scenarios where responses must be informed by the latest information, ideal for financial analysis tools that rely on current market data.
A hybrid approach merges these advantages, offering the specificity of fine-tuning with the contextual awareness of RAG, suitable for enterprises needing to keep pace with rapid information changes while maintaining deep domain relevance. As technology evolves, a hybrid model might offer the flexibility to adapt, providing a comprehensive solution that encompasses the strengths of both fine-tuning and RAG.
Evolution and future directions
As the landscape of artificial intelligence continues to evolve, so too do the methodologies and technologies at its core. Among these, Retrieval-Augmented Generation (RAG) and fine-tuning are experiencing significant advancements, propelling them toward new horizons of AI capabilities.
Advanced enhancements in RAG
Enhancing the retrieval-augmented generation pipeline
RAG has undergone significant transformations and advancements in each step of its pipeline. Each research paper on RAG introduces advanced methods to boost accuracy and relevance at every stage.
Let’s use the same query example from the basic RAG explanation: “What’s the latest breakthrough in renewable energy?”, to better understand these advanced techniques.
Pre-retrieval optimizations: Before the system begins to search, it optimizes the query for better outcomes. For our example, Query Transformations and Routing might break down the query into sub-queries like “latest renewable energy breakthroughs” and “new technology in renewable energy.” This ensures the search mechanism is fine-tuned to retrieve the most accurate and relevant information.
Enhanced retrieval techniques: During the retrieval phase, Hybrid Search combines keyword and semantic searches, ensuring a comprehensive scan for information related to our query. Moreover, by Chunking and Vectorization, the system breaks down extensive documents into digestible pieces, which are then vectorized. This means our query doesn’t just pull up general information but seeks out the precise segments of texts discussing recent innovations in renewable energy.
Post-retrieval refinements: After retrieval, Reranking and Filtering processes evaluate the gathered information chunks. Instead of simply using the top ‘k’ matches, these techniques rigorously assess the relevance of each piece of retrieved data. For our query, this could mean prioritizing a segment discussing a groundbreaking solar panel efficiency breakthrough over a more generic update on solar energy. This step ensures that the information used in generating the response directly answers the query with the most relevant and recent breakthroughs in renewable energy.
Through these advanced RAG enhancements, the system not only finds and utilizes information more effectively but also ensures that the final response to the query about renewable energy breakthroughs is as accurate, relevant, and up-to-date as possible.
Towards multimodal integration
RAG, traditionally focused on enhancing text-based language models by incorporating external data, is now also expanding its horizons towards a multimodal future.
Multimodal RAG integrates various types of data, such as images, audio, and video, alongside text, allowing AI models to generate responses that are not only informed by a vast array of textual information but also enriched by visual and auditory contexts.
This evolution signifies a move towards AI systems capable of understanding and interacting with the world more holistically, mimicking human-like comprehension across different sensory inputs.
In parallel, fine-tuning is transforming more parameter-efficient methods. Fine-tuning large language models (LLMs) presents a unique challenge for AI practitioners aiming to adapt these models to specific tasks without the overwhelming computational costs typically involved.
One such innovative technique is Parameter-Efficient Fine-Tuning (PEFT), which offers a cost-effective and efficient method for fine-tuning such a model.
Techniques like Low-Rank Adaptation (LoRA) are at the forefront of this change, enabling fine-tuning to be accomplished with significantly less computational overhead. LoRA and similar approaches adjust only a small subset of the model’s parameters, making fine-tuning not only more accessible but also more sustainable.
Specifically, it introduces a low-dimensional matrix that captures the essence of the downstream task, allowing for fine-tuning with minimal adjustments to the original model’s weights.
This method exemplifies how cutting-edge research is making it feasible to tailor LLMs for specialized applications without the prohibitive computational cost typically associated.
The emergence of long-context LLMs
The evolution toward long context LLMs – Source: Google Blog
As we embrace these advancements in RAG and fine-tuning, the recent introduction of Long Context LLMs, like Gemini 1.5 Pro, poses an intriguing question about the future necessity of these technologies. Gemini 1.5 Pro, for instance, showcases a remarkable capability with its 1 million token context window, setting a new standard for AI’s ability to process and utilize extensive amounts of information in one go.
The big deal here is how this changes the game for technologies like RAG and advanced fine-tuning. RAG was a breakthrough because it helped AI models to look beyond their training, fetching information from outside when needed, to answer questions more accurately. But now, with Long Context LLMs’ ability to hold so much information in memory, the question arises: Do we still need RAG anymore?
This doesn’t mean RAG and fine-tuning are becoming obsolete. Instead, it hints at an exciting future where AI can be both deeply knowledgeable, thanks to its vast memory, and incredibly adaptable, using technologies like RAG to fill in any gaps with the most current information.
In essence, Long Context LLMs could make AI more powerful by ensuring it has a broad base of knowledge to draw from, while RAG and fine-tuning techniques ensure that the AI remains up-to-date and precise in its answers. So the emergence of Long Context LLMs like Gemini 1.5 Pro does not diminish the value of RAG and fine-tuning but rather complements it.
Concluding Thoughts
The trajectory of AI, through the advancements in RAG, fine-tuning, and the emergence of long-context LLMs, reveals a future rich with potential. As these technologies mature, their combined interaction will make systems more adaptable, efficient, and capable of understanding and interacting with the world in ways that are increasingly nuanced and human-like.
The evolution of AI is not just a testament to technological advancement but a reflection of our continuous quest to create machines that can truly understand, learn from, and respond to the complex landscape of human knowledge and experience.
Vector embeddings have revolutionized the representation and processing of data for generative AI applications. The versatility of embedding tools has produced enhanced data analytics for its use cases.
In this blog, we will explore Google’s recent development of specialized embedding tools that particularly focus on promoting research in the fields of dermatology and pathology.
Let’s start our exploration with an overview of vector embedding tools.
What are vector embedding tools?
Vector embeddings are a specific embedding tool that uses vectors for data representation. While the direction of a vector determines its relationship with other data points in space, the length of a vector signifies the importance of the data point it represents.
A vector embedding tool processes input data by analyzing it and identifying key features of interest. The tool then assigns a unique vector to any data point based on its features. These are a powerful tool for the representation of complex datasets, allowing more efficient and faster data processing.
General embedding tools process a wide variety of data, capturing general features without focusing on specialized fields of interest. On the contrary, there are specialized embedding tools that enable focused and targeted data handling within a specific field of interest.
Specialized embedding tools are particularly useful in fields like finance and healthcare where unique datasets form the basis of information. Google has shared two specialized vector embedding tools, dealing with the demands of healthcare data processing.
However, before we delve into the details of these tools, it is important to understand their need in the field of medicine.
Why does healthcare need specialized embedding tools?
Embeddings are an important tool that enables ML engineers to develop apps that can handle multimodal data efficiently. These AI-powered applications using vector embeddings encompass various industries. While they deal with a diverse range of uses, some use cases require differentiated data-processing systems.
Healthcare is one such type of industry where specialized embedding tools can be useful for the efficient processing of data. Let’s explore major reasons for such differentiated use of embedding tools.
Medical data, ranging from patient history to imaging results, are crucial for diagnosis. These data sources, particularly from the field of dermatology and pathology, provide important information to medical personnel.
The slight variation of information in these sources requires specialized knowledge for the identification of relevant information patterns and changes. While regular embedding tools might fail at identifying the variations between normal and abnormal information, specialized tools can be created with proper training and contextual knowledge.
Data scarcity
While data is abundant in different fields and industries, healthcare information is often scarce. Hence, specialized embedding tools are needed to train on the small datasets with focused learning of relevant features, leading to enhanced performance in the field.
Focused and efficient data processing
The AI model must be trained to interpret particular features of interest from a typical medical image. This demands specialized tools that can focus on relevant aspects of a particular disease, assisting doctors in making accurate diagnoses for their patients.
In essence, specialized embedding tools bridge the gap between the vast amount of information within medical images and the need for accurate, interpretable diagnoses specific to each field in healthcare.
A look into Google’s embedding tools for healthcare research
The health-specific embedding tools by Google are focused on enhancing medical image analysis, particularly within the field of dermatology and pathology. This is a step towards addressing the challenge of developing ML models for medical imaging.
The two embedding tools – Derm Foundation and Path Foundation – are available for research use to explore their impact on the field of medicine and study their role in improving medical image analysis. Let’s take a look at their specific uses in the medical world.
Derm Foundation: A step towards redefining dermatology
It is a specialized embedding tool designed by Google, particularly for the field of dermatology within the world of medicine. It specifically focuses on generating embeddings from skin images, capturing the critical skin features that are relevant to diagnosing a skin condition.
The pre-training process of this specialized embedding tool consists of learning from a library of labeled skin images with detailed descriptions, such as diagnoses and clinical notes. The tool learns to identify relevant features for skin condition classification from the provided information, using it on future data to highlight similar features.
Derm Foundation outperforms BiT-M (a standard pre-trained image model) – Source: Google Research Blog
Some common features of interest for derm foundation when analyzing a typical skin image include:
Skin color variation: to identify any abnormal pigmentation or discoloration of the skin
Textural analysis: to identify and differentiate between smooth, rough, or scaly textures, indicative of different skin conditions
Pattern recognition: to highlight any moles, rashes, or lesions that can connect to potential abnormalities
Potential use cases of the Derm Foundation
Based on the pre-training dataset and focus on analyzing skin-specific features, Derm Foundation embeddings have the potential to redefine the data-processing and diagnosing practices for dermatology. Researchers can use this tool to develop efficient ML models. Some leading potential use cases for these models include:
Early detection of skin cancer
Efficient identification of skin patterns and textures from images can enable dermatologists to timely detect skin cancer in patients. Early detection can lead to better treatments and outcomes overall.
Improved classification of skin diseases
Each skin condition, such as dermatitis, eczema, and psoriasis, shows up differently on a medical image. A specialized embedding tool empowers the models to efficiently detect and differentiate between different skin conditions, leading to accurate diagnoses and treatment plans.
Hence, the Derm Foundation offers enhanced accuracy in dermatological diagnoses, faster deployment of models due to the use of pre-trained embeddings, and focused analysis by dealing with relevant features. It is a step towards a more accurate and efficient diagnosis of skin conditions, ultimately improving patient care.
Path Foundation: Revamping the world of pathology in medical sciences
While the Derm Foundation was specialized to study and analyze skin images, the Path Foundation embedding is designed to focus on images from pathology.
An outlook of SSL training used by Path Foundation – Source: Google Research Blog
It analyzes the visual data of tissue samples, focusing on critical features that can include:
Cellular structures: focusing on cell size, shape, or arrangement to identify any possible diseases
Tumor classification: differentiating between different types of tumors or assessing their aggressiveness
The pre-training process of the Path Foundation embedding comprises of labeled pathology images along with detailed descriptions and diagnoses relevant to them.
Potential use cases of the Path Foundation
Using the training dataset empowers the specialized embedding tool for efficient diagnoses in pathology. Some potential use cases within the field for this embedding tool include:
Improved cancer diagnosis
Improved analysis of pathology images can lead to timely detection of cancerous tissues. It will lead to earlier diagnoses and better patient outcomes.
Better pathology workflows
Analysis of pathology images is a time-consuming process that can be expedited with the use of an embedding tool. It will allow doctors to spend more time on complex cases while maintaining an improved workflow for their pathology diagnoses.
Thus, Path Foundation promises the development of pathology processes, supporting medical personnel in improved diagnoses and other medical processes.
Transforming healthcare with vector embedding tools
The use of embedding tools like Derm Foundation and Path Foundation has the potential to redefine data handling for medical processes. Specialized focus on relevant features offers enhanced diagnostic accuracy with efficient processes and workflows.
Moreover, the development of specialized ML models will address data scarcity often faced within healthcare when developing such solutions. It will also promote faster development of useful models and AI-powered solutions.
While the solutions will empower doctors to make faster and more accurate diagnoses, they will also personalize medicine for patients. Hence, embedding tools have the potential to significantly improve healthcare processes and treatments in the days to come.
This is the first blog in the series of RAG and finetuning, focusing on providing a better understanding of the two approaches.
RAG and finetuning: You’ve likely seen these terms tossed around on social media, hailed as the next big leap in artificial intelligence. But what do they really mean, and why are they so crucial in the evolution of AI?
To truly understand their significance, it’s essential to recognize the practical challenges faced by current language models, such as ChatGPT, renowned for their ability to mimic human-like text across essays, dialogues, and even poetry.
Yet, despite these impressive capabilities, their limitations became more apparent when tasked with providing up-to-date information on global events or expert knowledge in specialized fields.
Take, for instance, the FIFA World Cup.
Messi’s winning shot at the Fifa World Cup – Source: Economic Times
If you were to ask ChatGPT, “Who won the FIFA World Cup?” expecting details on the most recent tournament, you might receive an outdated response citing France as the champions despite Argentina’s triumphant victory in Qatar 2022.
ChatGPT’s response to an inquiry about the winner of the FIFA World Cup 2022
Moreover, the limitations of AI models extend beyond current events to specialized knowledge domains. Try asking ChatGPT for treatments in neurodegenerative diseases, a highly specialized medical field. The model might offer generic advice based on its training data but lacks depth or specificity – and, most importantly, accuracy.
Symptoms of Parkinson’s disease – Source: Neuro2go
GPT’s response to inquiry about Parkinson’s disease
These scenarios precisely illustrate the problem: a language model might generate text relevant to a past context or data but falls short when current or specialized knowledge is required.
RAG revolutionizes the way language models access and use information. Incorporating a retrieval step allows these models to pull in data from external sources in real-time. This means that when you ask a RAG-powered model a question, it doesn’t just rely on what it learned during training; instead, it can consult a vast, constantly updated external database to provide an accurate and relevant answer. This would bridge the gap highlighted by the FIFA World Cup example.
On the other hand, fine-tuning offers a way to specialize a general AI model for specific tasks or knowledge domains. Additional training on a focused dataset sharpens the model’s expertise in a particular area, enabling it to perform with greater precision and understanding.
This process transforms a jack-of-all-trades into a master of one, equipping it with the nuanced understanding required for tasks where generic responses just won’t cut it. This would allow it to perform as a seasoned medical specialist dissecting a complex case rather than a chatbot giving general guidelines to follow.
Curious about the LLM context augmentation approaches like RAG and fine-tuning and their benefits, trade-offs and use-cases? Tune in to this podcast with Co-founder and CEO of LlamaIndex now!
This blog will walk you through RAG and finetuning, unraveling how they work, why they matter, and how they’re applied to solve real-world problems. By the end, you’ll not only grasp the technical nuances of these methodologies but also appreciate their potential to transform AI systems, making them more dynamic, accurate, and context-aware.
Understanding the RAG LLM duo
What is RAG?
Retrieval-augmented generation (RAG) significantly enhances how AI language models respond by incorporating a wealth of updated and external information into their answers. It could be considered a model consulting an extensive digital library for information as needed.
Its essence is in the name: Retrieval, Augmentation, and Generation.
Retrieval
The process starts when a user asks a query, and the model needs to find information beyond its training data. It searches through a vast database that is loaded with the latest information, looking for data related to the user’s query.
Augmentation
Next, the information retrieved is combined, or ‘augmented,’ with the original query. This enriched input provides a broader context, helping the model understand the query in greater depth.
Generation
Finally, the language model generates a response based on the augmented prompt. This response is informed by the model’s training and the newly retrieved information, ensuring accuracy and relevance.
Why use RAG?
Retrieval-augmented generation (RAG) brings an approach to natural language processing that’s both smart and efficient. It solved many problems faced by current LLMs, and that’s why it’s the most talked about technique in the NLP space.
Always up-to-date
RAG keeps answers fresh by accessing the latest information. RAG ensures the AI’s responses are current and correct in fields where facts and data change rapidly.
Sticks to the facts
Unlike other models that might guess or make up details (a ” hallucinations ” problem), RAG checks facts by referencing real data. This makes it reliable, giving you answers based on actual information.
Flexible and versatile
RAG is adaptable, working well across various settings, from chatbots to educational tools and more. It meets the need for accurate, context-aware responses in a wide range of uses, and that’s why it’s rapidly being adapted in all domains.
To understand RAG further, consider when you interact with an AI model by asking a question like “What’s the latest breakthrough in renewable energy?”. This is when the RAG system springs into action. Let’s walk through the actual process.
A visual representation of an RAG pipeline
Query initiation and vectorization
Your query starts as a simple string of text. However, computers, particularly AI models, don’t understand text and its underlying meanings the same way humans do. To bridge this gap, the RAG system converts your question into an embedding, also known as a vector.
Why a vector, you might ask? Well, A vector is essentially a numerical representation of your query, capturing not just the words but the meaning behind them. This allows the system to search for answers based on concepts and ideas, not just matching keywords.
Searching the vector database
With your query now in vector form, the RAG system seeks answers in an up-to-date vector database. The system looks for the vectors in this database that are closest to your query’s vector—the semantically similar ones, meaning they share the same underlying concepts or topics.
But what exactly is a vector database?
Vector databases defined: A vector database stores vast amounts of information from diverse sources, such as the latest research papers, news articles, and scientific discoveries. However, it doesn’t store this information in traditional formats (like tables or text documents). Instead, each piece of data is converted into a vector during the ingestion process.
Why vectors?: This conversion to vectors allows the database to represent the data’s meaning and context numerically or into a language the computer can understand and comprehend deeply, beyond surface-level keywords.
Indexing: Once information is vectorized, it’s indexed within the database. Indexing organizes the data for rapid retrieval, much like an index in a textbook, enabling you to find the information you need quickly. This process ensures that the system can efficiently locate the most relevant information vectors when it searches for matches to your query vector.
The key here is that this information is external and not originally part of the language model’s training data, enabling the AI to access and provide answers based on the latest knowledge.
Selecting the top ‘k’ responses
From this search, the system selects the top few matches—let’s say the top 5. These matches are essentially pieces of information that best align with the essence of your question.
By concentrating on the top matches, the RAG system ensures that the augmentation enriches your query with the most relevant and informative content, avoiding information overload and maintaining the response’s relevance and clarity.
Augmenting the query
Next, the information from these top matches is used to augment the original query you asked the LLM. This doesn’t mean the system simply piles on data. Instead, it integrates key insights from these top matches to enrich the context for generating a response. This step is crucial because it ensures the model has a broader, more informed base from which to draw when crafting its answer.
Generating the response
Now comes the final step: generating a response. With the augmented query, the model is ready to reply. It doesn’t just output the retrieved information verbatim. Instead, it synthesizes the enriched data into a coherent, natural-language answer. For your renewable energy question, the model might generate a summary highlighting the most recent and impactful breakthrough, perhaps detailing a new solar panel technology that significantly increases power output. This answer is informative, up-to-date, and directly relevant to your query.
Understanding fine-tuning
What is fine-tuning?
Fine-tuning could be likened to sculpting, where a model is precisely refined, like shaping marble into a distinct figure. Initially, a model is broadly trained on a diverse dataset to understand general patterns—this is known as pre-training. Think of pre-training as laying a foundation; it equips the model with a wide range of knowledge.
Fine-tuning, then, adjusts this pre-trained model and its weights to excel in a particular task by training it further on a more focused dataset related to that specific task. From training on vast text corpora, pre-trained LLMs, such as GPT or BERT, have a broad understanding of language.
Fine-tuning adjusts these models to excel in targeted applications, from sentiment analysis to specialized conversational agents.
Why fine-tune?
The breadth of knowledge LLMs acquire through initial training is impressive but often lacks the depth or specificity required for certain tasks. Fine-tuning addresses this by adapting the model to the nuances of a specific domain or function, enhancing its performance significantly on that task without the need to train a new model from scratch.
The fine-tuning process
Fine-tuning involves several key steps, each critical to customizing the model effectively. The process aims to methodically train the model, guiding its weights toward the ideal configuration for executing a specific task with precision.
A look at the finetuning process
Selecting a task
Identify the specific task you wish your model to perform better on. The task could range from classifying emails into spam or not spam to generating medical reports from patient notes.
Choosing the right pre-trained model
The foundation of fine-tuning begins with selecting an appropriate pre-trained large language model (LLM) such as GPT or BERT. These models have been extensively trained on large, diverse datasets, giving them a broad understanding of language patterns and general knowledge.
The choice of model is critical because its pre-trained knowledge forms the basis for the subsequent fine-tuning process. For tasks requiring specialized knowledge, like medical diagnostics or legal analysis, choose a model known for its depth and breadth of language comprehension.
Preparing the specialized dataset
For fine-tuning to be effective, the dataset must be closely aligned with the specific task or domain of interest. This dataset should consist of examples representative of the problem you aim to solve. For a medical LLM, this would mean assembling a dataset comprised of medical journals, patient notes, or other relevant medical texts.
The key here is to provide the model with various examples it can learn from. This data must represent the types of inputs and desired outputs you expect once the model is deployed.
Reprocess the data
Before your LLM can start learning from this task-specific data, the data must be processed into a format the model understands. This could involve tokenizing the text, converting categorical labels into numerical format, and normalizing or scaling input features.
At this stage, data quality is crucial; thus, you’ll look out for inconsistencies, duplicates, and outliers, which can skew the learning process, and fix them to ensure cleaner, more reliable data.
After preparing this dataset, you divide it into training, validation, and test sets. This strategic division ensures that your model learns from the training set, tweaks its performance based on the validation set, and is ultimately assessed for its ability to generalize from the test set.
Once the pre-trained model and dataset are ready, you must better tailor the model to suit your specific task. An LLM comprises multiple neural network layers, each learning different aspects of the data.
During fine-tuning, not every layer is tweaked—some represent foundational knowledge that applies broadly. In contrast, the top or later layers are more plastic and customized to align with the specific nuances of the task. The architecture requires two key adjustments:
Layer freezing: To preserve the general knowledge the model has gained during pre-training, freeze most of its layers, especially the lower ones closer to the input. This ensures the model retains its broad understanding while you fine-tune the upper layers to be more adaptable to the new task.
Output layer modification: Replace the model’s original output layer with a new one tailored to the number of categories or outputs your task requires. This involves configuring the output layer to classify various medical conditions accurately for a medical diagnostic task.
Fine-tuning hyperparameters
With the model’s architecture now adjusted, we turn your attention to hyperparameters. Hyperparameters are the settings and configurations that are crucial for controlling the training process. They are not learned from the data but are set before training begins and significantly impact model performance. Key hyperparameters in fine-tuning include:
Learning rate: Perhaps the most critical hyperparameter in fine-tuning. A lower learning rate ensures that the model’s weights are adjusted gradually, preventing it from “forgetting” its pre-trained knowledge.
Batch size: The number of training examples used in one iteration. It affects the model’s learning speed and memory usage.
Epochs: The number of times the entire dataset is passed through the model. Enough epochs are necessary for learning, but too many can lead to overfitting.
Training process
With the dataset prepared, the model was adapted, and the hyperparameters were set, so the model is now ready to be fine-tuned.
The training process involves repeatedly passing your specialized dataset through the model, allowing it to learn from the task-specific examples, it involves adjusting the model’s internal parameters, the weights, and biases of those fine-tuned layers so the output predictions get as close to the desired outcomes as possible.
This is done in iterations (epochs), and thanks to the pre-trained nature of the model, it requires fewer epochs than training from scratch. Here is what happens in each iteration:
Forward pass: The model processes the input data, making predictions based on its current state.
Loss calculation: The difference between the model’s predictions and the actual desired outputs (labels) is calculated using a loss function. This function quantifies how well the model is performing.
Backward pass (Backpropagation): The gradients of the loss for each parameter (weight) in the model are computed. This indicates how the changes being made to the weights are affecting the loss.
Update weights: Apply an optimization algorithm to update the model’s weights, focusing on those in unfrozen layers. This step is where the model learns from the task-specific data, refining its predictions to become more accurate.
A tight feedback loop where you incessantly monitor the model’s validation performance guides you in preventing overfitting and determining when the model has learned enough. It gives you an indication of when to stop the training.
Evaluation and iteration
After fine-tuning, assess the model’s performance on a separate validation dataset. This helps gauge how well the model generalizes to new data. You do this by running the model against the test set—data it hadn’t seen during training.
Here, you look at metrics appropriate to the task, like BLEU and ROUGE for translation or summarization, or even qualitative evaluations by human judges, ensuring the model is ready for real-life application and isn’t just regurgitating memorized examples.
If the model’s performance is not up to par, you may need to revisit the hyperparameters, adjust the training data, or further tweak the model’s architecture.
For medical LLM applications, it is this entire process that enables the model to grasp medical terminologies, understand patient queries, and even assist in diagnosing from text descriptions—tasks that require deep domain knowledge.
Hence, this provides a comprehensive introduction to RAG and fine-tuning, highlighting their roles in advancing the capabilities of large language models (LLMs). Some key points to take away from this discussion can be put down as:
LLMs struggle with providing up-to-date information and excelling in specialized domains.
RAG addresses these limitations by incorporating external information retrieval during response generation, ensuring informative and relevant answers.
Fine-tuning refines pre-trained LLMs for specific tasks, enhancing their expertise and performance in those areas.
Covariant AI has emerged in the news with the introduction of its new model called RFM-1. The development has created a new promising avenue of exploration where humans and robots come together. With its progress and successful integration into real-world applications, it can unlock a new generation of AI advancements.
In this blog, we take a closer look at the company and its new model.
What is Covariant AI?
The company develops AI-powered robots for warehouses and distribution centers. It spun off in 2017 from OpenAI by its ex-research scientists, Peter Chen and Pieter Abbeel. Its robots are powered by a technology called the Covariant Brain, a machine-learning (ML) model to train and improve robots’ functionality in real-world applications.
The company has recently launched a new AL model that takes up one of the major challenges in the development of robots with human-like intelligence. Let’s dig deeper into the problem and its proposed solution.
What was the challenge?
Today’s digital world is heavily reliant on data to progress. Since generative AI is an important aspect of this arena, data and information form the basis of its development as well. So the development of enhanced functionalities in robots, and the appropriate training requires large volumes of data.
The limited amount of available data poses a great challenge, slowing down the pace of progress. It was a result of this challenge that OpenAI disbanded its robotics team in 2021. The data was insufficient to train the movements and reasoning of robots appropriately.
However, it all changed when Covariant AI introduced its new AI model.
Understanding the Covariant AI model
The company presented the world with RFM-1, its Robotics Foundation Model as a solution and a step ahead in the development of robotics. Integrating the characteristics of large language models (LLMs) with advanced robotic skills, the model is trained on a real-world dataset.
Covariant used its years of data from its AI-powered robots already operational in warehouses. For instance, the item-picking robots working in the warehouses of Crate & Barrel and Bonprix. With these large enough datasets, the challenge of data limitation was addressed, enabling the development of RFM-1.
Since the model leverages real-world data of robots operating within the industry, it is well-suited to train the machines efficiently. It brings together the reasoning of LLMs and the physical dexterity of robots which results in human-like learning of the robots.
An outlook of the features and benefits of RFM-1
Unique features of RFM-1
The introduction of the new AI model by Covariant AI has definitely impacted the trajectory of future developments in generative AI. While we still have to see how the journey progresses, let’s take a look at some important features of RFM-1.
Multimodal training capabilities
The RFM-1 is designed to deal with five different types of input: text, images, video, robot instructions, and measurements. Hence, it is more diverse in data processing than a typical LLM that is primarily focused on textual data input.
Integration with the physical world
Unlike your usual LLMs, this AI model engages with the physical world around it through a robot. The multimodal data understanding enables it to understand the surrounding environment in addition to the language input. It enables the robot to interact with the physical world.
Advanced reasoning skills
The advanced AI model not only processes the available information but engages with it critically. Hence, RFM-1 has enhanced reasoning skills that provide the robot with a better understanding of situations and improved prediction skills.
Benefits of RFM-1
The benefits of the AI model align with its unique features. Some notable advantages of this development are:
Enhanced performance of robots
The multimodal data enables the robots to develop a deeper understanding of their environments. It results in their improved engagement with the physical world, allowing them to perform tasks more efficiently and accurately. It will directly result in increased productivity and accuracy of business operations where the robots operate.
Improved adaptability
Based on the model’s improved reasoning skills, it ensure that the robots are equipped to understand, learn, and reason with new data. Hence, the robots become more versatile and adaptable to their changing environment.
Reduced reliance on programming
RFM-1 is built to constantly engage with and learn from its surroundings. Since it enables the robot to comprehend and reason with the changing input data, the reliance on pre-programmed instructions is reduced. The process of development and deployment becomes simpler and faster.
Hence, the multiple new features of RFM-1 empower it to create useful changes in the world of robotic development. Here’s a short video from Covariant AI, explaining and introducing their new AI model.
The future of RFM-1
The future of RFM-1 looks very promising, especially within the world of robotics. It has opened doors to a completely new possibility of developing a range of flexible and reliable robotic systems.
Covariant AI has taken the first step towards empowering commercial robots with an enhanced understanding of their physical world and language. Moreover, it has also introduced new avenues to integrate LLMs within the arena of generative AI applications.
You need the right tools to fully unleash the power of generative AI. A vector embedding model is one such tool that is a critical component of AI applications for creating realistic text, images, and more.
In this blog, we will explore vector embedding models and the various parameters to be on the lookout for when choosing an appropriate model for your AI applications.
What are vector embedding models?
Function of a vector embedding model
These act as data translators that can convert any data into a numerical code, specifically a vector of numbers. The model operates to create vectors that capture the meaning and semantic similarity between data objects. It results in the creation of a map that can be used to study data connections.
Moreover, the embedding models allow better control over the content and style of generated outputs, while dealing with multimodal data. Hence, it can deal with text, images, code, and other forms of data.
While we understand the role and importance of embedding models in the world of vector databases, the selection of right model is crucial for the success of an AI application. Let’s dig deeper into the details of making the relevant choice.
Since a vector embedding model forms the basis of your generative AI application, your choice is crucial for its success.
Factors to consider when choosing a vector embedding model
Below are some key factors to consider when exploring your model options.
Use case and desired outcomes
In any choice, your goals and objectives are the most important aspect. The same holds true for your embedding model selection. The use case and outcomes of your generative AI application guide your choice of model.
The type of task you want your app to perform is a crucial factor as different models capture specific aspects of data. The tasks can range from text generation and summarization to code completion and more. You must be clear about your goal before you explore the available options.
Moreover, data characteristics are of equal importance. Your data type – text, code, or image – must be compatible with your data format.
Model characteristics
The particular model characteristics of consideration include its accuracy, latency, and scalability. Accuracy refers to the ability of the model to correctly capture data relationships, including semantic meaning, word order, and linguistic nuances.
Latency is another important property which caters to real-time interactions of the application, improving model’s performance with reduced inference time. The size and complexity of data can impact this characteristic of an embedding model.
Moreover, to keep up with the rapidly advancing AI, it is important to choose a model that supports scalability. It also ensures that the model can cater to your growing dataset needs.
Practical factors
While app requirements and goals are crucial to your model choice, several practical aspects of the decision must also be considered. These primarily include computational resource requirements and cost of the model. While the former must match your data complexity, the latter should be within your specified budget.
Moreover, the available level of technical expertise also dictates your model choice. Since some vector embedding models require high technical expertise while others are more user-friendly, your strength of technical knowledge will determine your ease-of-use.
While these considerations address the various aspects of your organization-level goals and application requirements, you must consider some additional benchmarks and evaluation factors. Considering these benchmarks completes the highly important multifaceted approach of model selection.
Benchmarks for evaluating vector embedding models
Here’s a breakdown of some key benchmarks you can leverage:
Internal evaluation
These benchmarks focus on the quality of the embeddings for all tasks. Some common metrics of this evaluation include semantic relationships between words, word similarity in the embedding space, and word clustering. All these metrics collectively determine the quality of connections between embeddings.
External evaluation
It keeps track of the performance of embeddings in a specific task. Follwoing is a list of some of the metrics used for external evaluation:
ROUGE Score: It is called the Recall-Oriented Understudy for Gisting Evaluation. It deals with the performance of text summarization tasks, evaluating the overlap between generated and reference summaries.
BLEU Score: The Bilingual Evaluation Understudy, also called human evaluation measures the coherence and quality of outputs. This metric is particularly useful to track the quality of dialog generation.
MRR: It stands for Mean Reciprocal Rank. As the name suggests, it ranks the documents in the retrieved results based on their relevance.
A visual explanation of MRR – Source: Evidently AI
Benchmark Suites
The benchmark suites work by providing a standardized set of tasks and datasets to assess the models’ performance. It helps in making informed decisions as they highlight the strengths and weaknesses of of each model across a variety of tasks. Some common benchmark suites include:
BEIR (Benchmark for Evaluating Retrieval with BERT)
It focuses on information retrieval tasks by using a reference set that includes diverse information retrieval tasks such as question-answering, fact-checking, and entity retrieval. It provides datasets for retrieving relevant documents or passages based on a query, allowing for a comprehensive evaluation of a model’s capabilities.
The MTEB leaderboard is available on Hugging Face. It expands on BEIR’s foundation with 58 datasets and covering 112 languages. It enables evaluation of models against a wide range of linguistic contexts and use cases.
Its metrics and databases are suitable for tasks like text summarization, information retrieval, and semantic textual similarity, allowing you to see model performance on a broad range of tasks.
Hence, the different factors, benchmark suites, evaluation models, and metrics collectively present a multi-faceted approach towards selecting a relevant vector embedding model. However, alongside these quantitative metrics, it is important to incorporate human judgment into the process.
The final word
In navigating the performance of your generative AI applications, the journey starts with choosing an appropriate vector embedding model. Since the model forms the basis of your app performance, you must consider all the relevant factors in making a decision.
While you explore the various evaluation metrics and benchmarks, you must also carefully analyze the instances of your application’s poor performance. It will help in understanding the embedding model’s weaknesses, enabling you to choose the most appropriate one that ensures high-quality outputs.
AI chatbots are transforming the digital world with increased efficiency, personalized interaction, and useful data insights. While Open AI’s GPT and Google’s Gemini are already transforming modern business interactions, Anthropic AI recently launched its newest addition, Claude 3.
This blog explores the latest developments in the world of AI with the launch of Claude 3 and discusses the relative position of Anthropic’s new AI tool to its competitors in the market.
Let’s begin by exploring the budding realm of Claude 3.
What is Claude 3?
It is the most recent advancement in large language models (LLMs) by Anthropic AI to its claude family of AI models. It is the latest version of the company’s AI chatbot with an enhanced ability to analyze and forecast data. The chatbot can understand complex questions and generate different creative text formats.
Among its many leading capabilities is its feature to understand and respond in multiple languages. Anthropic has emphasized responsible AI development with Claude 3, implementing measures to reduce related issues like bias propagation.
Introducing the members of the Claude 3 family
Since the nature of access and usability differs for people, the Claude 3 family comes with various options for the users to choose from. Each choice has its own functionality, varying in data-handling capabilities and performance.
The Claude 3 family consists of a series of three models called Haiku, Sonnet, and Opus.
Members of the Claude 3 family – Source: Anthropic
Let’s take a deeper look into each member and their specialties.
Haiku
It is the fastest and most cost-effective model of the family and is ideal for basic chat interactions. It is designed to provide swift responses and immediate actions to requests, making it a suitable choice for customer interactions, content moderation tasks, and inventory management.
However, while it can handle simple interactions speedily, it is limited in its capacity to handle data complexity. It falls short in generating creative texts or providing complex reasonings.
Sonnet
Sonnet provides the right balance between the speed of Haiku and the intelligence of Opus. It is a middle-ground model among this family of three with an improved capability to handle complex tasks. It is designed to particularly manage enterprise-level tasks.
Hence, it is ideal for data processing, like retrieval augmented generation (RAG) or searching vast amounts of organizational information. It is also useful for sales-related functions like product recommendations, forecasting, and targeted marketing.
Moreover, the Sonnet is a favorable tool for several time-saving tasks. Some common uses in this category include code generation and quality control.
Opus
Opus is the most intelligent member of the Claude 3 family. It is capable of handling complex tasks, open-ended prompts, and sight-unseen scenarios. Its advanced capabilities enable it to engage with complex data analytics and content generation tasks.
Hence, Opus is useful for R&D processes like hypothesis generation. It also supports strategic functions like advanced analysis of charts and graphs, financial documents, and market trends forecasting. The versatility of Opus makes it the most intelligent option among the family, but it comes at a higher cost.
Ultimately, the best choice depends on the specific required chatbot use. While Haiku is the best for a quick response in basic interactions, Sonnet is the way to go for slightly stronger data processing and content generation. However, for highly advanced performance and complex tasks, Opus remains the best choice among the three.
Among the competitors
While Anthropic’s Claude 3 is a step ahead in the realm of large language models (LLMs), it is not the first AI chatbot to flaunt its many functions. The stage for AI had already been set with ChatGPT and Gemini. Anthropic has, however, created its space among its competitors.
Let’s take a look at Claude 3’s position in the competition.
Positioning Claude 3 among its competitors – Source: Anthropic
Performance Benchmarks
The chatbot performance benchmarks highlight the superiority of Claude 3 in multiple aspects. The Opus of the Claude 3 family has surpassed both GPT-4 and Gemini Ultra in industry benchmark tests. Anthropic’s AI chatbot outperformed its competitors in undergraduate-level knowledge, graduate-level reasoning, and basic mathematics.
Moreover, the Opus raises the benchmarks for coding, knowledge, and presenting a near-human experience. In all the mentioned aspects, Anthropic has taken the lead over its competition.
Comparing across multiple benchmarks – Source: Anthropic
For a deep dive into large language models, context windows, and content augmentation, watch this podcast now!
Data processing capacity
In terms of data processing, Claude 3 can consider much larger text at once when formulating a response, unlike the 64,000-word limit on GPT-4. Moreover, Opus from the Anthropic family can summarize up to 150,000 words while ChatGPT’s limit is around 3000 words for the same task.
It also possesses multimodal and multi-language data-handling capacity. When coupled with enhanced fluency and human-like comprehension, Anthropic’s Claude 3 offers better data processing capabilities than its competitors.
Ethical considerations
The focus on ethics, data privacy, and safety makes Claude 3 stand out as a highly harmless model that goes the extra mile to eliminate bias and misinformation in its performance. It has an improved understanding of prompts and safety guardrails while exhibiting reduced bias in its responses.
Which AI chatbot to use?
Your choice relies on the purpose for which you need an AI chatbot. While each tool presents promising results, they outshine each other in different aspects. If you are looking for a factual understanding of language, Gemini is your go-to choice. ChatGPT, on the other hand, excels in creative text generation and diverse content creation.
However, striding in line with modern content generation requirements and privacy, Claude 3 has come forward as a strong choice. Alongside strong reasoning and creative capabilities, it offers multilingual data processing. Moreover, its emphasis on responsible AI development makes it the safest choice for your data.
To sum it up
Claude 3 emerges as a powerful LLM, boasting responsible AI, impressive data processing, and strong performance. While each chatbot excels in specific areas, Claude 3 shines with its safety features and multilingual capabilities. While access is limited now, Claude 3 holds promise for tasks requiring both accuracy and ingenuity. Whether it’s complex data analysis or crafting captivating poems, Claude 3 is a name to remember in the ever-evolving world of AI chatbots.
AI disasters caused notable instances where the application of AI has led to negative consequences or exacerbations of pre-existing issues.
Artificial Intelligence (AI) has a multifaceted impact on society, ranging from the transformation of industries to ethical and environmental concerns. AI holds the promise of revolutionizing many areas of our lives by increasing efficiency, enabling innovation, and opening up new possibilities in various sectors.
The growth of the AI market is only set to boom. In fact, McKinsey projects an economic impact of $6.1-7.9T annually.
One significant impact of AI is on disaster risk reduction (DRR), where it aids in early warning systems and helps in projecting potential future trajectories of disasters. AI systems can identify areas susceptible to natural disasters and facilitate early responses to mitigate risks.
However, the use of AI in such critical domains raises profound ethical, social, and political questions, emphasizing the need to design AI systems that are equitable and inclusive.
AI also affects employment and the nature of work across industries. With advancements in generative AI, there is a transformative potential for AI to automate and augment business processes, although the technology is still maturing and cannot yet fully replace human expertise in most fields.
Moreover, the deployment of AI models requires substantial computing power, which has environmental implications. For instance, training and operating AI systems can result in significant CO2 emissions due to the energy-intensive nature of the supporting server farms.
Consequently, there is growing awareness of the environmental footprint of AI and the necessity to consider the potential climate implications of widespread AI adoption.
In alignment with societal values, AI development faces challenges like ensuring data privacy and security, avoiding biases in algorithms, and maintaining accessibility and equity. The decision-making processes of AI must be transparent, and there should be oversight to ensure AI serves the needs of all communities, particularly marginalized groups.
That said, let’s have a quick look at the 5 most famous AI disasters that occurred recently:
5 famous AI disasters
AI is not inherently causing disasters in society, but there have been notable instances where the application of AI has led to negative consequences or exacerbations of pre-existing issues:
Generative AI in legal research
An attorney named Steven A. Schwartz used OpenAI’s ChatGPT for legal research, which led to the submission of at least six nonexistent cases in a lawsuit’s brief against Colombian airline Avianca.
The brief included fabricated names, docket numbers, internal citations, and quotes. The use of ChatGPT resulted in a fine of $5,000 for both Schwartz and his partner Peter LoDuca, and the dismissal of the lawsuit by US District Judge P. Kevin Castel.
Machine learning in healthcare
AI tools developed to aid hospitals in diagnosing or triaging COVID-19 patients were found to be ineffective due to training errors.
The UK’s Turing Institute reported that these predictive tools made little to no difference. Failures often stem from the use of mislabeled data or data from unknown sources.
An example includes a deep learning model for diagnosing COVID-19 that was trained on a dataset with scans of patients in different positions and was unable to accurately diagnose the virus due to these inconsistencies.
AI in real estate at Zillow
Zillow utilized a machine learning algorithm to predict home prices for its Zillow Offers program, aiming to buy and flip homes efficiently.
However, the algorithm had a median error rate of 1.9%, and, in some cases, as high as 6.9%, leading to the purchase of homes at prices that exceeded their future selling prices.
This misjudgment resulted in Zillow writing down $304 million in inventory and led to a workforce reduction of 2,000 employees, or approximately 25% of the company.
Bias in AI recruitment tools:
Amazon’s case is not detailed in the provided sources, but referencing similar issues of bias in recruitment tools, it’s notable that AI algorithms can unintentionally incorporate biases from the data they are trained on.
In AI recruiting tools, this means if the training datasets have more resumes from one demographic, such as men, the algorithm might show preference to those candidates, leading to discriminatory hiring practices.
AI in recruiting software at iTutorGroup:
iTutorGroup’s AI-powered recruiting software was programmed with criteria that led it to reject job applicants based on age. Specifically, the software discriminated against female applicants aged 55 and over, and male applicants aged 60 and over.
This resulted in over 200 qualified candidates being unfairly dismissed by the system. The US Equal Employment Opportunity Commission (EEOC) took action against iTutorGroup, which led to a legal settlement. iTutorGroup agreed to pay $365,000 to resolve the lawsuit and was required to adopt new anti-discrimination policies as part of the settlement.
Ethical concerns for organizations – Post-deployment of AI
The use of AI within organizations brings forth several ethical concerns that need careful attention. Here is a discussion on the rising ethical concerns post-deployment of AI:
Data Privacy and Security:
The reliance on data for AI systems to make predictions or decisions raises significant concerns about privacy and security. Issues arise regarding how data is gathered, stored, and used, with the potential for personal data to be exploited without consent.
Bias in AI:
When algorithms inherit biases present in the data they are trained on, they may make decisions that are discriminating or unjust. This can result in unfair treatment of certain demographics or individuals, as seen in recruitment, where AI could prioritize certain groups over others unconsciously.
Accessibility and Equity:
Ensuring equitable access to the benefits of AI is a major ethical concern. Marginalized communities often have lesser access to technology, which may leave them further behind. It is crucial to make AI tools accessible and beneficial to all, to avoid exacerbating existing inequalities.
Accountability and Decision-Making:
The question of who is accountable for decisions made by AI systems is complex. There needs to be transparency in AI decision-making processes and the ability to challenge and appeal AI-driven decisions, especially when they have significant consequences for human lives.
Overreliance on Technology:
There is a risk that overreliance on AI could lead to neglect of human judgment. The balance between technology-aided decision-making and human expertise needs to be maintained to ensure that AI supports, not supplants, human roles in critical decision processes.
Infrastructure and Resource Constraints:
The implementation of AI requires infrastructure and resources that may not be readily available in all regions, particularly in developing countries. This creates a technological divide and presents a challenge for the widespread and fair adoption of AI.
These ethical challenges require organizations to establish strong governance frameworks, adopt responsible AI practices, and engage in ongoing dialogue to address emerging issues as AI technology evolves.
Tune into this podcast to explore how AI is reshaping our world and the ethical considerations and risks it poses for different industries and the society.
How can organizations protect themselves from AI risks?
To protect themselves from AI disasters, organizations can follow several best practices, including:
Adherence to Ethical Guidelines:
Implement transparent data usage policies and obtain informed consent when collecting data to protect privacy and ensure security .
Bias Mitigation:
Employ careful data selection, preprocessing, and ongoing monitoring to address and mitigate bias in AI models .
Equity and Accessibility:
Ensure that AI-driven tools are accessible to all, addressing disparities in resources, infrastructure, and education .
Human Oversight:
Retain human judgment in conjunction with AI predictions to avoid overreliance on technology and to maintain human expertise in decision-making processes.
Infrastructure Robustness:
Invest in the necessary infrastructure, funding, and expertise to support AI systems effectively, and seek international collaboration to bridge the technological divide.
Verification of AI Output:
Verify AI-generated content for accuracy and authenticity, especially in critical areas such as legal proceedings, as demonstrated by the case where an attorney submitted non-existent cases in a court brief using output from ChatGPT. The attorney faced a fine and acknowledged the importance of verifying information from AI sources before using them.
One real use case to illustrate these prevention measures is the incident involving iTutorGroup. The company faced a lawsuit due to its AI-powered recruiting software automatically rejecting applicants based on age.
To prevent such discrimination and its legal repercussions, iTutorGroup agreed to adopt new anti-discrimination policies as part of the settlement. This case demonstrates that organizations must establish anti-discrimination protocols and regularly review the criteria used by AI systems to prevent biases.
AI is not inherently causing disasters in society, but there have been notable instances where the application of AI has led to negative consequences or exacerbations of pre-existing issues.
It’s important to note that while these are real concerns, they represent challenges to be addressed within the field of AI development and deployment rather than AI actively causing disasters.
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. This blog delves into a detailed comparison between the two data management techniques.
In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. Hence, databases are important for strategic data handling and enhanced operational efficiency.
However, before we dig deeper into the types of databases, let’s understand them better.
Understanding databases
Databases are a structured way to store and organize data effectively. It involves multiple data handling processes, like updating, deleting, or changing information. These are important for efficient data organization, security, and control.
Rules are put in place by databases to ensure data integrity and minimize redundancy. Moreover, organized storage of data facilitates data analysis, enabling retrieval of useful insights and data patterns. It also facilitates integration with different applications to enhance their functionality with organized access to data.
In data science, databases are important for data preprocessing, cleaning, and integration. Data scientists often rely on databases to perform complex queries and visualize data. Moreover, databases allow the storage of training datasets, facilitating model training and validation.
While databases are vital to data management, they have also developed over time. The changing technological world has led to a transition in available databases. Hence, the digital arena has gradually shifted from traditional to vector databases.
Since the shift is still underway, you can access both kinds of databases. However, it is important to understand the uses, limitations, and functions of both databases to understand which is more suitable for your organization. Let’s explore the arguments around the debate of traditional vs vector databases.
Exploring the traditional vs vector databases debate
In comparing the two categories of databases, we must explore a common set of factors to understand the basic differences between them. Hence, this blog will explore the debate from a few particular aspects, highlighting the characteristics of both traditional and vector databases in the process.
Traditional vs vector databases
Data models
Traditional databases:
They use a relational model that consists of a structured tabular form. Data is contained in tables divided into rows and columns. While each column represents a particular field, each row represents a single record within that field. Hence, the data is well-organized and maintains a well-defined relationship between different entities.
This relational data model holds a rigid schema, defining the structure of the data upfront. While it ensures high data integrity, it also makes the model inflexible in handling diverse and evolving data types.
Vector databases:
Instead of a relational row and column structure, vector databases use a vector-based model consisting of a multidimensional array of numbers. Each data point is stored as a vector in a three-dimensional space, representing different features and properties of data.
Unlike a traditional database, the vector representation is well-suited to store unstructured data. It also allows easier handling of complex data points, making it a versatile data model. Its flexible schema allows better adaptability but at the cost of data integrity.
Suggestion:
Based on the data models of both databases, it can be said that when making a choice, you must find the right balance between maintaining data integrity and flexible data-handling capabilities. Understanding your database requirements between these two properties will help you towards an accurate option.
They rely on Structured Query Language (SQL), designed to navigate through relational databases. It provides a standardized way to interact with data, allowing data manipulation in the form of updating, inserting, deleting, and more.
It presents a highly focused method of addressing queries where data is filtered using exact matches, comparisons, and logical operators. SQL querying has long been present in the industry, hence it comes with a rich ecosystem of support.
Vector databases:
Unlike a declarative language like SQL, vector databases execute querying through API calls. These can vary based on the vector database you use. The APIs perform similarity searches and nearest-neighbor operations as part of the querying process.
The process is based on retrieving similar data points to a query from the multidimensional vector space. It leverages indexing and search techniques that are suitable for complex vector databases.
Suggestion:
Hence, query language specifications are highly particular to your choice of a database. You would have to rely on either SQL for traditional databases or work with API calls if you are dealing with vector spaces for data storage.
Indexing techniques
Traditional databases:
Different data representation in a Hash and B-Tree Index – Source: IT Tutorial
Indexing techniques for traditional databases include B-trees and hash indexes that are designed for structured data. B-trees is the most common method that organizes data in a hierarchical tree format. It assists in the efficient sorting and retrieval of data.
Hash indexes rely on hash functions to map data to particular locations in an index. On accessing this location, you can retrieve the actual data stored there. They are integral for point queries where exact matches are known.
Vector databases:
HNSW and IVF are indexing methods that specialize in handling vector databases. These differentiated techniques optimize similarity searches in high-dimensional vector data.
A visual representation of HNSW – Source: Pinecone
HNSW stands for Hierarchical Navigable Small World which facilitates rapid proximity searches. It creates a multi-layer navigation graph to represent the vector space, creating a network of shortcuts to narrow down the search space to a small subset of similar vectors.
IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster. A file records vectors that belong to each cluster. It enables comparison and detailed data search within clusters.
Both methods aim to enhance the similarity search in vector databases. While HNSW speeds up the process, IVF also increases its efficiency.
Suggestion:
While traditional indexing techniques optimize precise queries and efficient data manipulation in structured data, vector database methods are designed for similarity searches within high-dimensional data, handling complex queries such as nearest neighbor searches in machine learning applications.
These databases manage transactional workloads with a focus on data integrity (ACID compliance) and support complex querying capabilities. However, their performance is limited due to their design of vertical scalability, making it a costly and hardware-dependent process to handle large data volumes.
Vector databases:
Vector databases provide distinct performance advantages in environments requiring quick insights from large volumes of complex data, enabling efficient search operations. Moreover, its horizontal scalability design promotes the distribution of data management across multiple machines, making it a cost-effective process.
Suggestion:
Performance-based decisions can be made by finding the right balance between data integrity and flexible data handling, similar to the consideration of their data model differences. However, the horizontal and vertical scalability highlights that vector databases are more cost-efficient for large data volumes.
Use cases
Traditional databases:
They are ideal for applications that rely on structured data and require transactional safety while managing data records and performing complex queries. Some common use cases include financial systems, E-commerce platforms, customer relationship management (CRM), and human resource (HR) systems.
Vector databases:
They are useful for complex and multimodal datasets, often associated with complex machine learning (ML) tasks. Some important use cases include natural language processing (NLP), fraud detection, recommendation systems, and real-time personalization.
The differences in use cases highlight the varied strengths of both databases. You cannot undermine one over the other but understand both databases better to make the right choice for your data. Traditional databases remain the backbone for structured data while vector databases are better adapted for modern datasets.
The final verdict
Traditional databases are suitable for small or medium-sized datasets where retrieval of specific data is required from well-defined links of information. Vector databases, on the other hand, are better for large unstructured datasets with a focus on similarity searches.
Hence, the clash of databases can be seen as a tradition meeting innovation. Traditional databases excel in structured realms, while vector databases revolutionize with speed in high-dimensional data. The final verdict of making the right choice hinges on your specific use cases.
In the dynamic world of machine learning and natural language processing (NLP), database optimization is crucial for effective data handling.
Hence, the pivotal role of vector databases in the efficient storage and retrieval of embeddings has become increasingly apparent. These sophisticated platforms have emerged as indispensable tools, providing a robust infrastructure for managing the intricate data structures generated by large language models.
This blog embarks on a comprehensive exploration of the profound significance of vector databases. We will delve into the different types of vector databases, analyzing their unique features and applications in large language model (LLM) scenarios. Additionally, real-world case studies will illuminate the tangible impact of these databases across diverse applications.
Understanding Vector Databases and Their Significance
Vector databases represent purpose-built platforms meticulously designed to address the intricate challenges posed by the storage and retrieval of vector embeddings.
In the landscape of NLP applications, these embeddings serve as the lifeblood, capturing intricate semantic and contextual relationships within vast datasets. Traditional databases, grappling with the high-dimensional nature of these embeddings, falter in comparison to the efficiency and adaptability offered by vector databases.
Visual representation of traditional and vector databases
The uniqueness of vector databases lies in their tailored ability to efficiently manage complex data structures, a critical requirement for handling embeddings generated from large language models and other intricate machine learning models.
These databases serve as the hub, providing an optimized solution for the nuanced demands of NLP tasks. In a landscape where the boundaries of machine learning are continually pushed, vector databases stand as pillars of adaptability, efficiently catering to the specific needs of high-dimensional vector storage and retrieval.
Understanding vector databases
Exploring Different Types of Vector Databases and Their Features
The vast landscape of vector databases unfolds in diverse types, each armed with unique features meticulously crafted for specific use cases.
Types of vector databases
Weaviate: Graph-Driven Semantic Understanding
Weaviate stands out for seamlessly blending graph database features with powerful vector search capabilities, making it an ideal choice for NLP applications requiring advanced semantic understanding and embedding exploration.
With a user-friendly RESTful API, client libraries, and a WebUI, Weaviate simplifies integration and management for developers. The API ensures standardized interactions, while client libraries abstract complexities, and the WebUI offers an intuitive graphical interface.
Weaviate’s cohesive approach empowers developers to leverage its capabilities effortlessly, making it a standout solution in the evolving landscape of data management for NLP.
DeepLake: Open-Source Scalability and Speed
DeepLake, an open-source powerhouse, excels in the efficient storage and retrieval of embeddings, prioritizing scalability and speed. With a distributed architecture and built-in support for horizontal scalability, DeepLake emerges as the preferred solution for managing vast NLP datasets.
Its implementation of an Approximate Nearest Neighbor (ANN) algorithm, specifically based on the Product Quantization (PQ) method, not only guarantees rapid search capabilities but also maintains pinpoint accuracy in similarity searches.
DeepLake is meticulously designed to address the challenges of handling large-scale NLP data, offering a robust and high-performance solution for storage and retrieval tasks.
Deep Lake architectural pattern
Faiss by Facebook: High-Performance Similarity Search
Faiss, known for its outstanding performance in similarity searches, offers a diverse range of optimized indexing methods for swift retrieval of nearest neighbors. With support for GPU acceleration and a user-friendly Python interface, Faiss firmly establishes itself in the vector database landscape.
This versatility enables seamless integration with NLP pipelines, enhancing its effectiveness across a wide spectrum of machine learning applications. Faiss stands out as a powerful tool, combining performance, flexibility, and ease of integration for robust similarity search capabilities in diverse use cases.
Milvus: Scaling Heights with Open-Source Flexibility
Milvus, an open-source tool, stands out for its emphasis on scalability and GPU acceleration. Its ability to scale up and work with graphics cards makes it great for managing large NLP datasets. Milvus is designed to be distributed across multiple machines, making it ideal for handling massive amounts of data.
It easily integrates with popular libraries like Faiss, Annoy, and NMSLIB, giving developers more choices for organizing data and improving the accuracy and efficiency of vector searches. The diversity of vector databases ensures that developers have a nuanced selection of tools, each catering to specific requirements and use cases within the expansive landscape of NLP and machine learning.
Efficient Storage and Retrieval of Vector Embeddings for LLM Applications
Efficiently leveraging vector databases for the storage and retrieval of embeddings in the world of large language models (LLMs) involves a meticulous process. This journey is multifaceted, encompassing crucial considerations and strategic steps that collectively pave the way for optimized performance.
Choosing the Right Database
The foundational step in this intricate process is the selection of a vector database that seamlessly aligns with the scalability, speed, and indexing requirements specific to the LLM project at hand.
The decision-making process involves a careful evaluation of the project’s intricacies, understanding the nuances of the data, and forecasting future scalability needs. The chosen vector database becomes the backbone, laying the groundwork for subsequent stages in the embedding storage and retrieval journey.
Integration with NLP Pipelines
Leveraging the provided RESTful APIs and client libraries is the key to ensuring a harmonious integration of the chosen vector database within NLP frameworks and LLM applications.
This stage is characterized by a meticulous orchestration of tools, ensuring that the vector database seamlessly becomes an integral part of the larger ecosystem. The RESTful APIs serve as the conduit, facilitating communication and interaction between the database and the broader NLP infrastructure.
Optimizing Search Performance
The crux of efficient storage and retrieval lies in the optimization of search performance. Here, developers delve into the intricacies of the chosen vector database, exploring and utilizing specific indexing methods and GPU acceleration capabilities.
These nuanced optimizations are tailored to the unique demands of LLM applications, ensuring that vector searches are not only precise but also executed with optimal speed. The performance optimization stage serves as the fine-tuning mechanism, aligning the vector database with the intricacies of large language models.
Language-specific Indexing
In scenarios where LLM applications involve multilingual content, the choice of a vector database supporting language-specific indexing and retrieval capabilities becomes paramount. This consideration reflects the diverse linguistic landscape that the LLM is expected to navigate.
Language-specific indexing ensures that the vector database comprehends and processes linguistic nuances, ultimately leading to accurate search results across different languages.
Incremental Updates
A forward-thinking strategy involves the consideration of vector databases supporting incremental updates. This capability is crucial for LLM applications characterized by dynamically changing embeddings.
The vector database’s ability to efficiently store and retrieve these dynamic embeddings, adapting in real-time to the evolving nature of the data, becomes a pivotal factor in ensuring the sustained accuracy and relevance of the LLM application.
This multifaceted approach to embedding storage and retrieval for LLM applications ensures that developers navigate the complexities of large language models with precision and efficacy, harnessing the full potential of vector databases.
Case Studies: Real-world Impact of Database Optimization with Vector Databases
The real-world impact of vector databases unfolds through compelling case studies across diverse industries, showcasing their versatility and efficacy in varied applications.
Case Study 1: Semantic Understanding in Chatbots
The implementation of Weaviate’s vector database in an AI chatbot leveraging large language models exemplifies the real-world impact on semantic understanding. Weaviate facilitates the efficient storage and retrieval of semantic embeddings, enabling the chatbot to interpret user queries within context.
The result is a chatbot that provides accurate and contextually relevant responses, significantly enhancing the user experience.
Case Study 2: Multilingual NLP Applications
VectorStore’s language-specific indexing and retrieval capabilities take center stage in a multilingual NLP platform.
The case study illuminates how VectorStore efficiently manages and retrieves embeddings across different languages, providing contextually relevant results for a global user base. This underscores the adaptability of vector databases in diverse linguistic landscapes.
Understanding multilingual NLP applications
Case Study 3: Image Generation and Similarity Search
In the world of image generation and similarity search, a company harnesses vector databases to streamline the storage and retrieval of image embeddings. By representing images as high-dimensional vectors, the vector database enables swift and accurate similarity searches, enhancing tasks such as image categorization, duplicate detection, and recommendation systems.
The real-world impact extends to the world of visual content, underscoring the versatility of vector databases.
Case Study 4: Movie and Product Recommendations
E-commerce and movie streaming platforms optimize their recommendation systems through the power of vector databases. Representing movies or products as high-dimensional vectors based on attributes like genre, cast, and user reviews, the vector database ensures personalized recommendations.
This personalized touch elevates the user experience, leading to higher conversion rates and improved customer retention. The case study vividly illustrates how vector databases contribute to the dynamic landscape of recommendation systems.
Case Study 5: Sentiment Analysis in Social Media
A social media analytics company transforms sentiment analysis with the efficient use of vector databases. Representing text snippets or social media posts as high-dimensional vectors, the vector database enables rapid and accurate sentiment analysis. This real-time analysis of large volumes of text data provides valuable insights, allowing businesses and marketers to track public opinion, detect trends, and identify potential brand reputation issues.
Case Study 6: Fraud Detection in Financial Services
The application of vector databases in a financial services company amplifies fraud detection capabilities. By representing transaction patterns as high-dimensional vectors, the vector database enables rapid similarity searches to identify suspicious or anomalous behavior.
In the world of financial services, where timely detection is paramount, vector databases provide the efficiency and accuracy needed to safeguard customer accounts. The case study emphasizes the real-world impact of vector databases in enhancing security measures.
The final word
In conclusion, the complex interplay of efficient storage and retrieval of vector embeddings using vector databases is at the heart of the success of machine learning and NLP applications, particularly in the expansive landscape of large language models.
This journey has unveiled the profound significance of vector databases, explored the diverse types and features they bring to the table, and provided insights into their application in LLM scenarios.
Real-world case studies have served as representations of their tangible impact, showcasing their ability to enhance semantic understanding, multilingual support, image generation, recommendation systems, sentiment analysis, and fraud detection.
By assimilating the insights shared in this exploration, developers embark on a path that brings them closer to harnessing the full potential of vector databases. These databases, with their adaptability, efficiency, and real-world impact, emerge as indispensable allies in the dynamic landscape of machine learning and NLP applications.
In the drive for AI-powered innovation in the digital world, NVIDIA’s unprecedented growth has led it to become a frontrunner in this revolution. Found in 1993, NVIDIA began as a result of three electrical engineers – Malachowsky, Curtis Priem, and Jen-Hsun Huang – aiming to enhance the graphics of video games.
However, the history is evidence of the dynamic nature of the company and its timely adaptability to the changing market needs. Before we analyze the continued success of NVIDIA, let’s explore its journey of unprecedented growth from 1993 onwards.
An outline of NVIDIA’s growth in the AI industry
With a valuation exceeding $2 trillion in March 2024 in the US stock market, NVIDIA has become the world’s third-largest company by market capitalization.
A Glance at NVIDIA’s Journey
From 1993 to 2024, the journey is marked by different stages of development that can be summed up as follows:
The early days (1993)
The birth of NVIDIA in 1993 was the early days of the company when they focused on creating 3D graphics for gaming and multimedia. It was the initial stage of growth where an idea among three engineers had taken shape in the form of a company.
The rise of GPUs (1999)
NVIDIA stepped into the AI industry with its creation of graphics processing units (GPUs). The technology paved a new path of advancements in AI models and architectures. While focusing on improving the graphics for video gaming, the founders recognized the importance of GPUs in the world of AI.
GPU became the game-changer innovation by NVIDIA, offering a significant leap in processing power and creating more realistic 3D graphics. It turned out to be an opening for developments in other fields of video editing, design, and many more.
Introducing CUDA (2006)
After the introduction of GPUs, the next turning point came with the introduction of CUDA – Compute Unified Device Architecture. The company released this programming toolkit for easy accessibility of the processing power of NVIDIA’s GPUs.
It unlocked the parallel processing capabilities of GPUs, enabling developers to leverage their use in other industries. As a result, the market for NVIDIA broadened as it progressed from a graphics card company to a more versatile player in the AI industry.
Emerging as a key player in deep learning (2010s)
The decade was marked by focusing on deep learning and navigating the potential of AI. The company shifted its focus to producing AI-powered solutions.
Some of the major steps taken at this developmental stage include:
Emergence of Tesla series: Specialized GPUs for AI workloads were launched as a powerful tool for training neural networks. Its parallel processing capability made it a go-to choice for developers and researchers.
Launch of Kepler Architecture: NVIDIA launched the Kepler architecture in 2012. It further enhanced the capabilities of GPU for AI by improving its compute performance and energy efficiency.
Introduction of cuDNN Library: In 2014, the company launched its cuDNN (CUDA Deep Neural Network) Library. It provided optimized codes for deep learning models. With faster training and inference, it significantly contributed to the growth of the AI ecosystem.
DRIVE Platform: With its launch in 2015, NVIDIA stepped into the arena of edge computing. It provides a comprehensive suite of AI solutions for autonomous vehicles, focusing on perception, localization, and decision-making.
NDLI and Open Source: Alongside developing AI tools, they also realized the importance of building the developer ecosystem. NVIDIA Deep Learning Institute (NDLI) was launched to train developers in the field. Moreover, integrating open-source frameworks enhanced the compatibility of GPUs, increasing their popularity among the developer community.
RTX Series and Ray Tracing: In 2018, NVIDIA enhanced the capabilities of its GPUs with real-time ray tracing, known as the RTX Series. It led to an improvement in their deep learning capabilities.
Dominating the AI landscape (2020s)
The journey of growth for the company has continued into the 2020s. The latest is marked by the development of NVIDIA Omniverse, a platform to design and simulate virtual worlds. It is a step ahead in the AI ecosystem that offers a collaborative 3D simulation environment.
The AI-assisted workflows of the Omniverse contribute to efficient content creation and simulation processes. Its versatility is evident from its use in various industries, like film and animation, architectural and automotive design, and gaming.
Hence, the outline of NVIDIA’s journey through technological developments is marked by constant adaptability and integration of new ideas. Now that we understand the company’s progress through the years since its inception, we must explore the many factors of its success.
Factors behind NVIDIA’s unprecedented growth
The rise of NVIDIA as a leading player in the AI industry has created a buzz recently with its increasing valuation. The exponential increase in the company’s market space over the years can be attributed to strategic decisions, technological innovations, and market trends.
Factors Impacting NVIDIA’s Growth
However, in light of its journey since 1993, let’s take a deeper look at the different aspects of its success.
Recognizing GPU dominance
The first step towards growth is timely recognition of potential areas of development. NVIDIA got that chance right at the start with the development of GPUs. They successfully turned the idea into a reality and made sure to deliver effective and reliable results.
The far-sighted approach led to enhancing the GPU capabilities with parallel processing and the development of CUDA. It resulted in the use of GPUs in a wider variety of applications beyond their initial use in gaming. Since the versatility of GPUs is linked to the diversity of the company, growth was the future.
Early and strategic shift to AI
NVIDIA developed its GPUs at a time when artificial intelligence was also on the brink of growth an development. The company got a head start with its graphics units that enabled the strategic exploration of AI.
The parallel architecture of GPUs became an effective solution for training neural networks, positioning the company’s hardware solution at the center of AI advancement. Relevant product development in the form of Tesla GPUs and architectures like Kepler, led the company to maintain its central position in AI development.
The continuous focus on developing AI-specific hardware became a significant contributor to ensuring the GPUs stayed at the forefront of AI growth.
Building a supportive ecosystem
The company’s success also rests on a comprehensive approach towards its leading position within the AI industry. They did not limit themselves to manufacturing AI-specific hardware but expanded to include other factors in the process.
Collaborations with leading tech giants – AWS, Microsoft, and Google among others – paved the way to expand NVIDIA’s influence in the AI market. Moreover, launching NDLI and accepting open-source frameworks ensured the development of a strong developer ecosystem.
As a result, the company gained enhanced access and better credibility within the AI industry, making its technology available to a wider audience.
Capitalizing on ongoing trends
The journey aligned with some major technological trends and shifts, like COVID-19. The boost in demand for gaming PCs gave rise to NVIDIA’s revenues. Similarly, the need for powerful computing in data centers rose with cloud AI services, a task well-suited for high-performing GPUs.
The latest development of the Omniverse platform puts NVIDIA at the forefront of potentially transformative virtual world applications. Hence, ensuring the company’s central position with another ongoing trend.
With a culture focused on innovation and strategic decision-making, NVIDIA is bound to expand its influence in the future. Jensen Huang’s comment “This year, every industry will become a technology industry,” during the annual J.P. Morgan Healthcare Conference indicates a mindset aimed at growth and development.
As AI’s importance in investment portfolios rises, NVIDIA’s performance and influence are likely to have a considerable impact on market dynamics, affecting not only the company itself but also the broader stock market and the tech industry as a whole.
Overall, NVIDIA’s strong market position suggests that it will continue to be a key player in the evolving AI landscape, high-performance computing, and virtual production.